
AI Spec-Driven Development com Kiro e outras IDEs agênticas
Descubra como AI Spec-Driven Development resolve Context Drift e melhora qualidade do desenvolvimento com IA usando Kiro e IDEs agênticas
AI Spec-Driven Development é um processo de desenvolvimento de software muito poderoso que visa trazer previsibilidade de resultados ao usualmente caótico desenvolvimento com IA baseado em prompts.
O desenvolvimento orientado por prompt herda muito dos problemas e desafios do Vibe Coding, e por mais diligentes que sejamos, a experiência apresenta uma tendência de degradar rapidamente, levando a um acúmulo de erros progressivo, que espirala num fim cheio de frustração e perda de tempo.
Neste artigo entenderemos por que a maioria dos problemas surge da falta de contexto e estrutura nos prompts iniciais, e como uma dinâmica que parte da Especificação do Software consegue gerar resultados muito melhores, com qualidade superior e, de fato, acelerando o processo.
Onde os Problemas Começam
Quando menos se espera, as coisas começam a dar errado e acabamos gastando mais tempo consertando erro da IA do que implementando coisas novas. Muitas vezes, há uma ilusão de produtividade acelerada, quando a realidade é que estamos trocando seis por meia dúzia.
Um das causas de problemas, especialmente em sessões mais longas de desenvolvimento, é a tendência de muitos modelos de LLMs a degradar a performance à medida que a conversa continua.
Este fenômeno é conhecido como Context Drifting (ou também Context Rot) e vem sendo alvo de estudo intenso. Há várias formas deste “desvio de contexto” acontecer, entre elas o acúmulo de erros e a saturação de contexto da LLM.
graph LR
subgraph "📈 Performance da IA ao Longo do Tempo"
A[🚀 Início<br/>Alta Performance] --> B[📊 Desenvolvimento<br/>Performance Estável]
B --> C[⚠️ Degradação<br/>Context Drift]
C --> D[❌ Problemas<br/>Erros Acumulados]
A -.-> E[💡 Contexto Rico<br/>Prompts Claros]
B -.-> F[📝 Informações<br/>Acumulando]
C -.-> G[🔄 Saturação<br/>Contexto Bloat]
D -.-> H[🚫 Alucinações<br/>Imprevisibilidade]
end
subgraph "🔧 Soluções"
I[📋 Spec-Driven<br/>Development] --> J[✂️ Dividir Para<br/>Conquistar]
J --> K[🔄 Nova Sessão<br/>Contexto Limpo]
K --> L[📚 Contexto<br/>Estruturado]
end
D --> I
style A fill:#2d5a2d,stroke:#4a7c4a,stroke-width:2px,color:#ffffff
style B fill:#5a4a2d,stroke:#7c6a4a,stroke-width:2px,color:#ffffff
style C fill:#5a5a2d,stroke:#7c7c4a,stroke-width:2px,color:#ffffff
style D fill:#5a2d2d,stroke:#7c4a4a,stroke-width:2px,color:#ffffff
style I fill:#2d4a5a,stroke:#4a6a7c,stroke-width:2px,color:#ffffff
style J fill:#4a2d5a,stroke:#6a4a7c,stroke-width:2px,color:#ffffff
style K fill:#2d5a4a,stroke:#4a7c6a,stroke-width:2px,color:#ffffff
style L fill:#4a4a4a,stroke:#6a6a6a,stroke-width:2px,color:#ffffff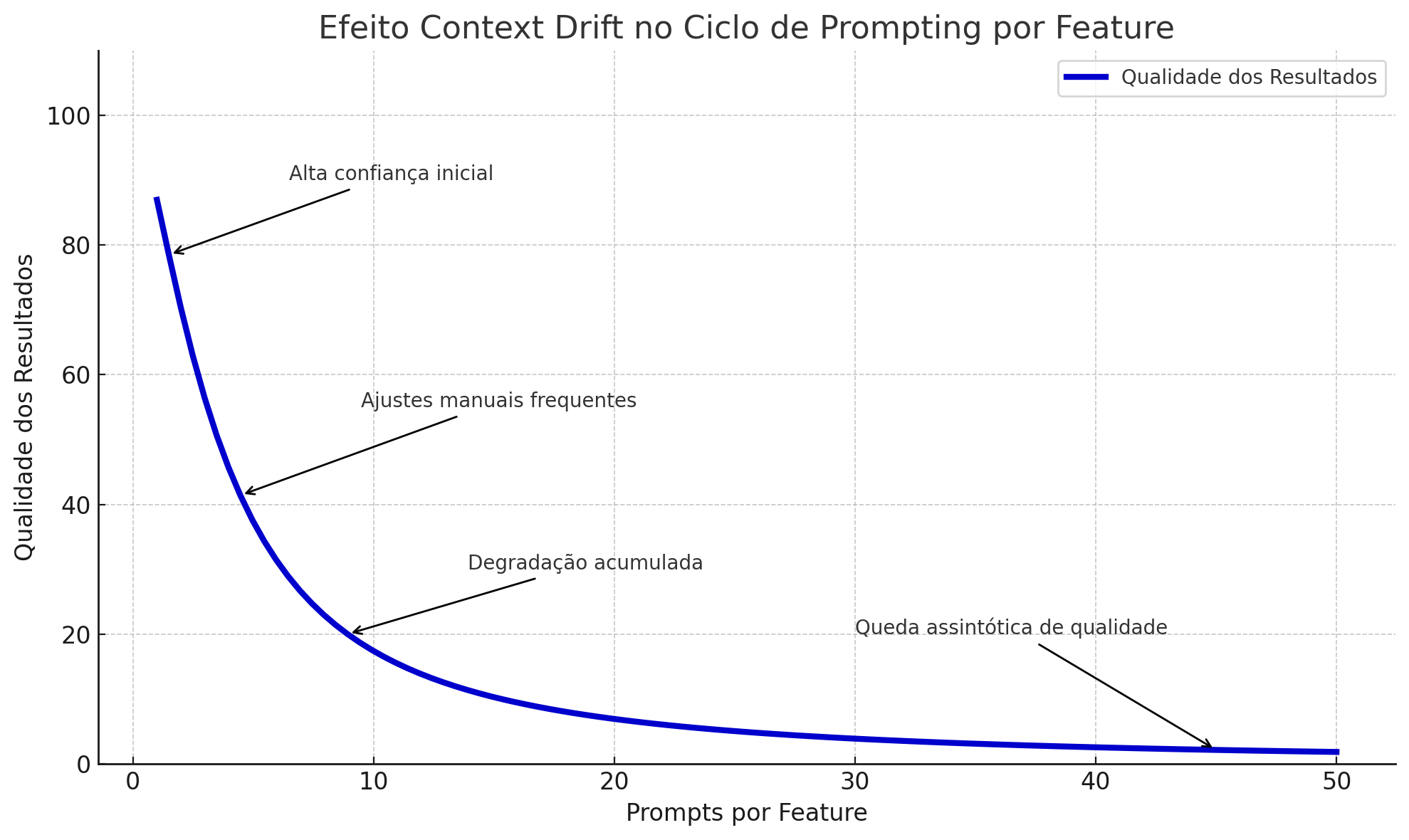
Desvio por Acúmulo de Erros
A linguagem natural é o veículo de interação com os agentes de codificação em IDEs como Cursor e Claude Code. Mas ao mesmo tempo em que a linguagem natural reduz a barreira de entrada para a programação, introduz desafios consideráveis de interpretabilidade que não existiam nas linguagens formais de programação.
Ou seja, grande parte dos erros acumulados ocorre por problemas de comunicação. Aquilo que é expresso de forma mal elaborada e imprecisa no prompt, e especialmente tudo aquilo que fica de fora, e que vai fazer falta.
Ou seja, mais do que nunca precisamos ser bons comunicadores. Precisamos nos lembrar de que a comunicação efetiva não se trata do que foi dito, mas do que foi entendido.
Saturação de Contexto das LLMs
Todas as LLMs atuais possuem uma janela de contexto com a qual conseguem trabalhar. Apesar de apresentarem um limite claro, como 128 mil tokens no caso GPT-4o da OpenAI, ou 2 milhões de tokens do Gemini 1.5 do Google, estes modelos começam a apresentar degradação na performance à medida em que o contexto é preenchido com mais informação, num fenômeno conhecido como Saturação de Contexto (ou Context Bloat).
A tabela abaixo ilustra os pontos em que a performance começa a degradar em vários modelos:
| Modelo | Janela Máxima de Contexto | Ponto de Início da Degradação Significativa |
|---|---|---|
| Claude 3.7 Sonnet | 200.000 tokens | 60.000 ~ 80.000 tokens (usabilidade prática) |
| OpenAI GPT-4o | 128.000 tokens | Degradação visível após 64.000 – 100.000 tokens |
| Gemini 2.5 Pro | 1.000.000 tokens | 200.000 ~ 400.000 tokens (média) |
Esta degração pode se manifestar de várias formas, como:
- Esquecimento de informações que já foram determinadas, como requerimentos ignorados
- Aumento na frequência de alucinações
- Imprevisibilidade das ações do agente
Algumas ferramentas “context-hungry”, como o Cline, podem encher o contexto rapidamente, chegando rapidamente a cenários imprevisíveis, muito parecidos com sessões longas. Elas fazem isso adicionando muitos arquivos ao contexto para tentar obter resultados rápidos de alta qualidade, à custa de uma degradação mais rápida do contexto.
Recomendações para evitar problemas com saturação de contexto:
- Aplicar a estratégia Dividir Para Conquistar: tarefas pequenas e bem definidas trazem resultados melhores, e este é um dos trunfos do Spec-Driven Development, como veremos mais abaixo.
- Começar uma nova conversa com o agente logo que possível, evitando seguir por muito tempo na mesma sessão e misturar assuntos
Desvio de Arquitetura
Também conhecido como Architectural Drift, o Desvio de Arquitetura é um fenômeno que ocorre em decorrência dos problemas citados anteriormente. Com um contexto pobre o modelo fica cego a certos padrões arquiteturais, e as implementações geradas tendem a divergir cada vez mais dos padrões previamente estabelecidos, levando a todo tipo de problemas e gerando muito retrabalho.
O acúmulo de erros, por sua vez, leva a implementações potencialmente esdrúxulas, totalmente incompatíveis com um sistema em produção.
Spec-Driven Development
A metodologia Spec-Driven Development tomou forma há alguns anos com o objetivo de criar um processo de desenvolvimento em que a especificação do software é utilizada tratada como fonte única da verdade, e todo o desenvolvimento parte dali. A especificação de APIs com OpenAPI (antigamente conhecido como Swagger) é frequentemente utilizada como especificação de referência, especialmente em negócios cujas APIs fazem parte do Core Business.
A especificação OpenAPI e outras tecnologias descrevem com clareza muitos aspectos importantes de um sistema:
- Descrevem uma API Rest em arquivos JSON ou YAML bem estruturados
- Definem todos os endpoints da API e operações disponíveis (GET, UPDATE, PUT, PATCH, DELETE)
- Descrição clara de entradas e saídas de cada operação
- Descrição dos métodos de autenticação
- Documentação de outros aspectos, como licença e termos de uso
Além disso, uma especificação formal pertite criar fluxos automatizados com vários tipos de artefatos valiosos:
- Online Playground
- Exemplos de Código
- Suítes de Teste
- Collections para Postman ou Insomnia
- Documentação OpenAPI (que pode ser exportada para) Documentação clara e padronizada das funções do sistema, parâmetros, retornos
- Geração automatizada de client SDKs
De forma simplificada, podemos dizer que todo novo desenvolvimento parte da atualização da documentação técnica e revisão por todo o time, para só então seguir para desenvolvimento. Desta forma criamos um ciclo que mantém a documentação sempre atualizada, gera alinhamento entre o time, e um software que reflete mais precisamente a especificação.
flowchart TD
A[📋 Atualizar Especificação Técnica] --> B[👥 Revisão pelo Time]
B --> C{✅ Aprovado?}
C -->|Não| A
C -->|Sim| D[💻 Desenvolvimento]
D --> E[🧪 Testes]
E --> F{✅ Passou nos Testes?}
F -->|Não| D
F -->|Sim| G[🚀 Deploy]
G --> H[📊 Monitoramento]
H --> I[🔄 Feedback & Melhorias]
I --> A
style A fill:#e1f5fe
style B fill:#f3e5f5
style D fill:#e8f5e8
style E fill:#fff3e0
style G fill:#fce4ec
style H fill:#f1f8e9
style I fill:#fafafaQuando o processo parte da especificação técnica, podemos chamá-lo também de Tech Spec-Driven Development, pois seu foco está na especificação técnica:
- OpenAPI Specification
- Diagramas de Arquitetura
- Diagramas de Banco de Dados
- Outros
Mas a especificação pode partir também dos Requisitos Funcionais e Não-Funcionais, além de User Stories, como veremos a seguir.
AI Spec-Driven Development
Como já vimos anteriormente, o desenvolvimento orientado por prompts tende a ter resultados aquém das expectativas para qualquer desenvolvimento não trivial. Isso pode ser mitigado ou revertido com a aplicação de boas técnicas de Engenharia de Prompt.
Mas além das técnicas de prompt engineering que já vêm crescendo em popularidade e se tornando cada vez mais sofisticadas, uma abordagem que vem se mostrando muito eficaz em melhorar os resultados obtidos é a separação das fases de Planejamento e Execução.
E é aí que o Spec-Driven Development brilha! Aplicado ao desenvolvimento com agentes de IA, podemos criar um fluxo que eleva o agente de um simples codificador, a co-autor dos requisitos, do desenvolvendo técnico e arquitetural da aplicação, do design, e então do planejamento e acompanhamento das tarefas. Esses elementos oferecem estrutura clara e enriquecem o contexto disponível ao agente, ao mesmo tempo em que mantém o desenvolvedor sempre no controle, e permite que o time revise e refine o plano, antes de implementar uma linha de código.
flowchart TD
subgraph "🤖 Evolução do Agente de IA"
A[📝 Codificador Simples<br/>Prompt → Código] --> B[📋 Co-autor de Requisitos<br/>Análise de User Stories]
B --> C[🏗️ Co-autor Técnico<br/>Arquitetura & Design]
C --> D[📊 Co-autor de Planejamento<br/>Tarefas & Estimativas]
D --> E[🔄 Co-autor de Acompanhamento<br/>Monitoramento & Refinamento]
end
subgraph "👥 Controle Humano"
F[👨💻 Desenvolvedor<br/>Sempre no Controle] --> G[👥 Time<br/>Revisão & Refinamento]
G --> H[✅ Aprovação<br/>Antes da Implementação]
end
subgraph "📚 Contexto Enriquecido"
I[📋 Especificação Técnica] --> J[🎯 Requisitos Funcionais]
J --> K[⚙️ Requisitos Não-Funcionais]
K --> L[👤 User Stories]
L --> M[🏛️ Diagramas de Arquitetura]
end
E -.-> F
H --> A
M -.-> C
style A fill:#ffebee
style B fill:#e3f2fd
style C fill:#e8f5e8
style D fill:#fff3e0
style E fill:#f3e5f5
style F fill:#fafafa
style G fill:#f1f8e9
style H fill:#e0f2f1A abordagem do Kiro
A Amazon lançou recentemente uma nova IDE baseada no Visual Studio Code chamada Kiro, que está em fase de testes, e traz como principal diferencial a opção de desenvolver usando o modo Spec.
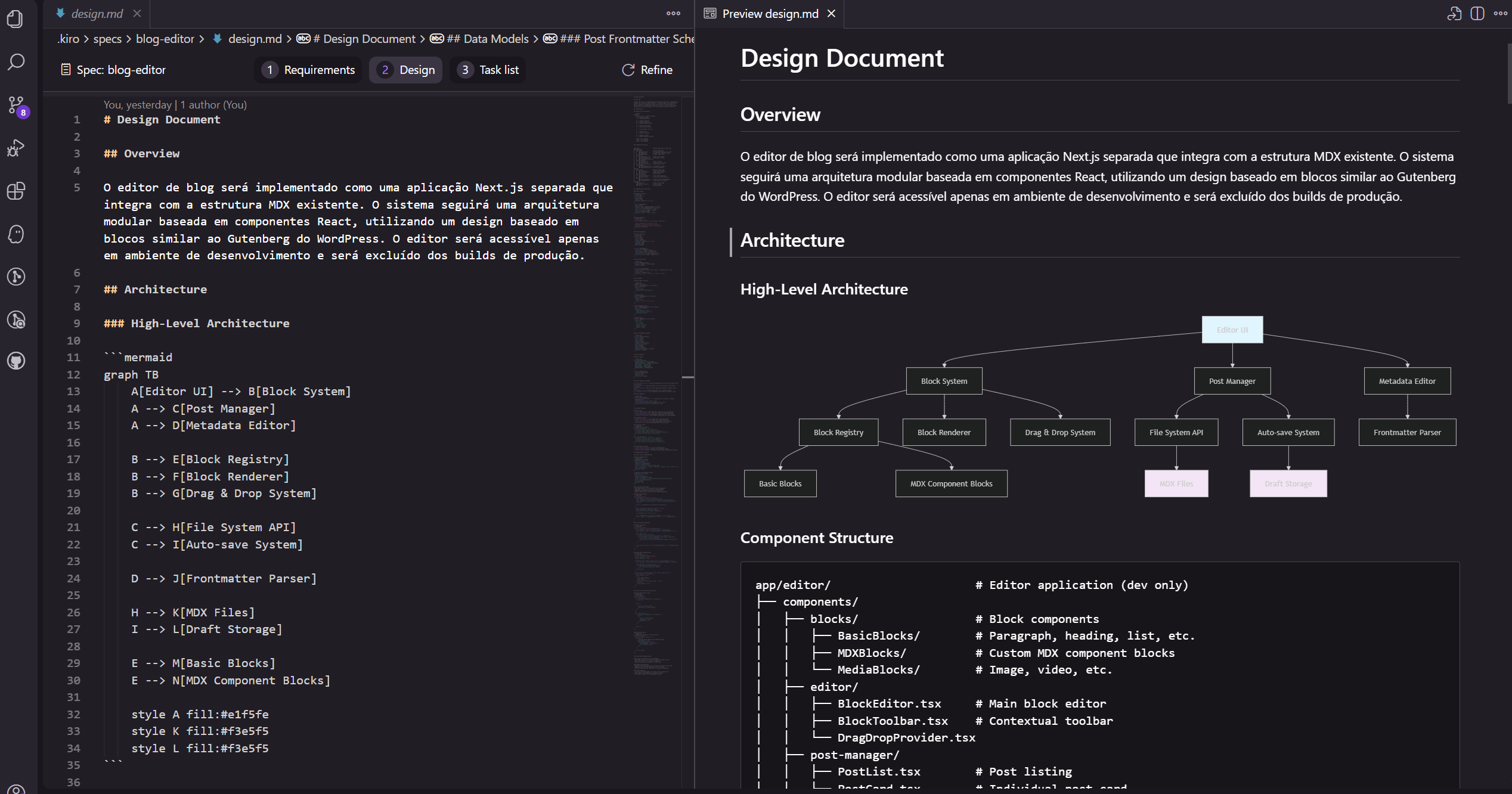
Quando descrevemos o que queremos atingir no modo Spec, o Kiro vai criar a especificação num diretório .kiro/specs, e vai dar um nome para a especificação. No exemplo abaixo, vemos que foi criada uma especificação chamada blog-editor.
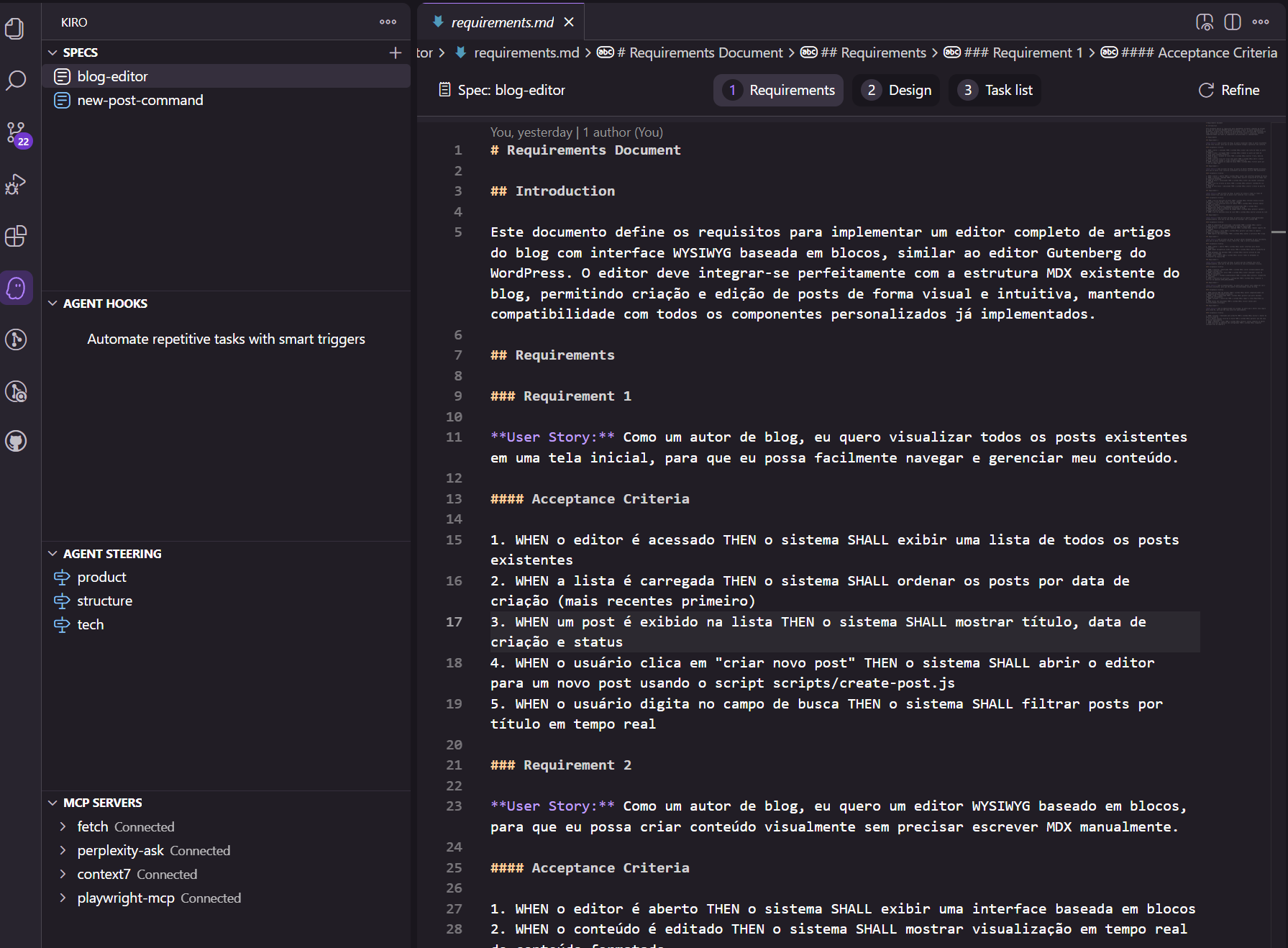
As especificações de requisitos são geradas pelo Kiro seguem o formato EARS (Easy Approach to Requirements Syntax). Elas incluem uma introdução da funcionalidade especificada no documento, seguida por uma lista de requisitos. Cada Requisito, por sua vez, é formado por duas partes: uma Estória de Usuário, e uma lista de Critérios de Aceite, como pode ser visto na imagem acima.
Segue abaixo um exemplo de Requisito no formato EARS, conforme implementado pelo Kiro:
### Requirement 1
**User Story:** Como um autor de blog, eu quero visualizar todos os posts existentes em uma tela inicial, para que eu possa facilmente navegar e gerenciar meu conteúdo.
#### Acceptance Criteria
1. WHEN o editor é acessado THEN o sistema SHALL exibir uma lista de todos os posts existentes
2. WHEN a lista é carregada THEN o sistema SHALL ordenar os posts por data de criação (mais recentes primeiro)
3. WHEN um post é exibido na lista THEN o sistema SHALL mostrar título, data de criação e status
4. WHEN o usuário clica em "criar novo post" THEN o sistema SHALL abrir o editor para um novo post usando o script scripts/create-post.js
5. WHEN o usuário digita no campo de busca THEN o sistema SHALL filtrar posts por título em tempo realEstes requisitos podem ser refinados pelo desenvolvedor, com ou sem ajuda do agente, versionados e compartilhados com o time, tornando o processo realmente colaborativo. O mesmo vale para os arquivos de design e tarefas.
Quando sinalizamos ao Kiro que os requisitos estão bem definidos, seguimos para a próxima fase do processo: a etapa de Design. Nesta fase é que serão trabalhados os aspectos de design e arquitetura da solução. Os elementos que aparecerão nesta etapa dependem muito do que está sendo trabalhado, mas geralmente incluirão tópicos como:
- Arquitetura da aplicação
- Contratos de APIs e banco de dados
- Estratégia de testes
- Frameworks e bibliotecas
- Considerações de segurança
- Interfaces e Contratos
- Outros
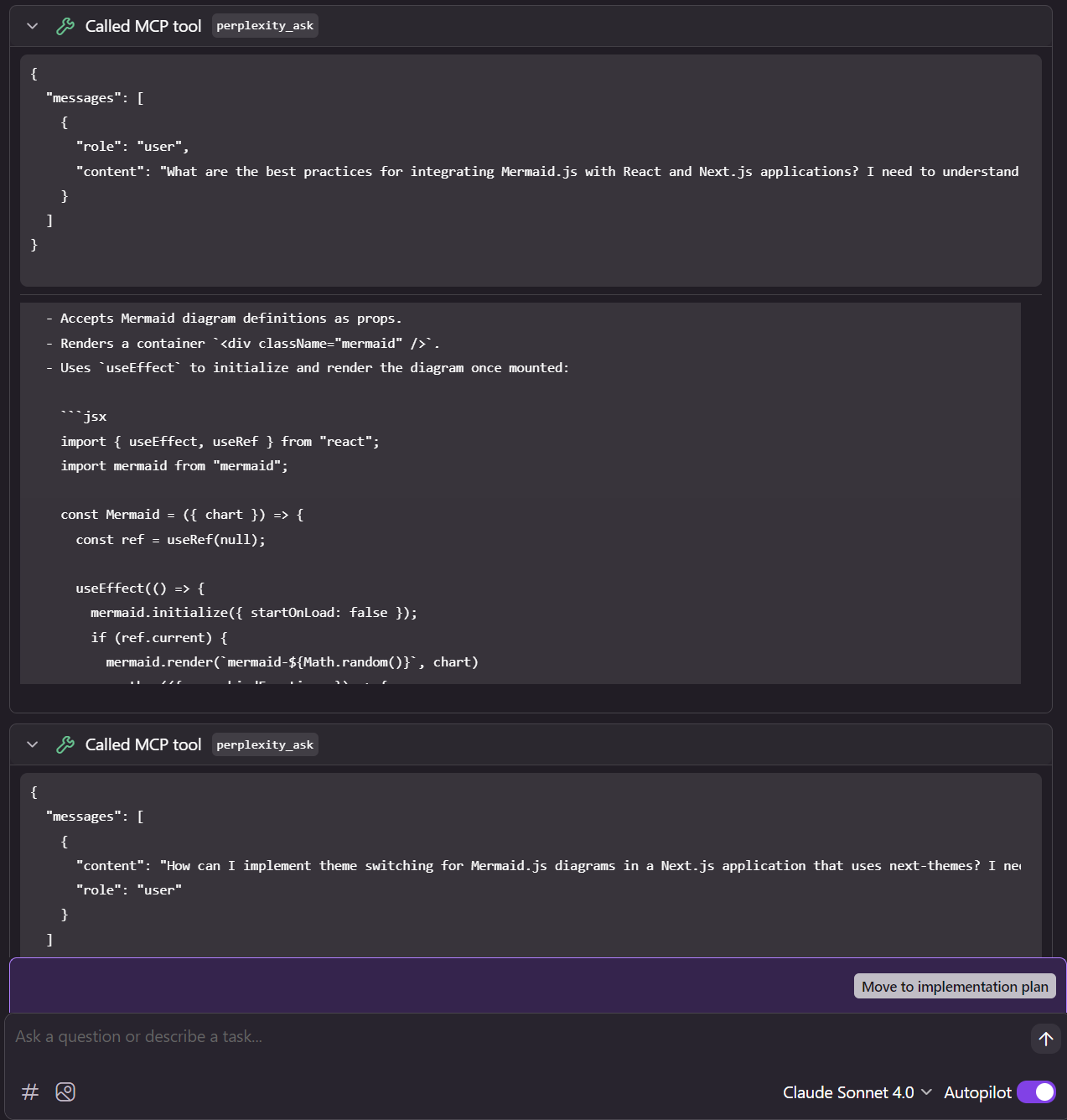
Como o Kiro suporta servidores MCP, ele também pode usá-los durante a fase de design. No meu caso, frequentemente ele utiliza o Perplexity para pesquisar melhores práticas de implementação de algum tipo de funcionalidade.
Após refinado, seguimentos para a criação das tarefas, que visa capturar simultaneamete os requisitos e os detalhes de design da solução. Essas tarefas são ordenadas de forma que os requisitos vão sendo gradualmente construídos em direção a compleção da tarefa.
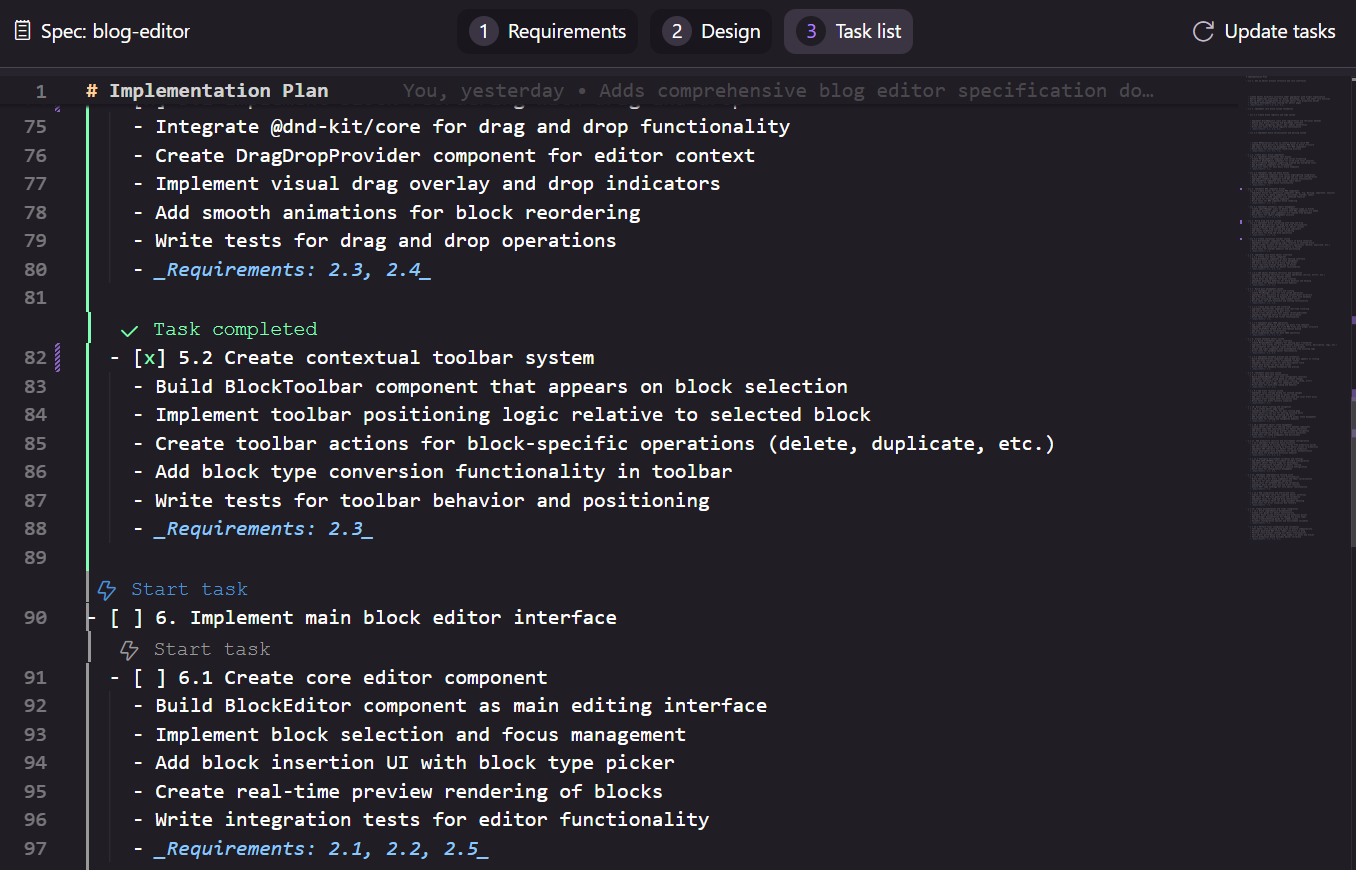
Uma das funcionalidades que gostei muito são os gatilhos para iniciar tarefas. Ao clicar ele dispara um novo agente, com o contexto necessário para executá-la. Isso também nos dá liberdade de escolher a ordem da execução das tarefas, que não precisa ser necessariamente sequencial.

Dica
Com a especificação completa, tendo requisitos, design e tarefas descritas, a execução poderá ser feita em outras ferramentas. Testei essa abordagem com o Augment Code, mas também funcionaria no Cursor, Windsurf, Cline, Claude Code, Gemini CLI e outras ferramentas.
Basta usar um prompt semelhante a este:
Implemente o item 6.1 do @.kiro\specs\blog-editor\tasks.md.
Referências: @.kiro\specs\blog-editor\design.md @.kiro\specs\blog-editor\requirements.md.
Marque a tarefa como concluída ao final.
Spec-Driven em outras ferramentas como Cursor
Apesar de outras IDEs agênticas não possuírem essa sistemática de Spec-Driven Design implementada nativamente, podemos criar fluxos de trabalho muito semelhantes utilizando os recursos disponíveis nas IDEs.
Algumas ferramentas como o Cursor e o Cline permitem criar o que chamamos de Custom Modes. Um “Modo Customizado” é uma configuração de agente, que nos permite criar um comportamento completamente diferente daquele experienciado pela maioria das pessoas com o Agente Padrão.
Um Custom Mode permite criar um agente com características próprias:
- System Prompt guiando seu comportamento
- Modelo de LLM
- Ferramentas nativas disponíveis para o agente (leitura, escrita e exclusão de arquivos, )
- Servidores MCP disponíveis
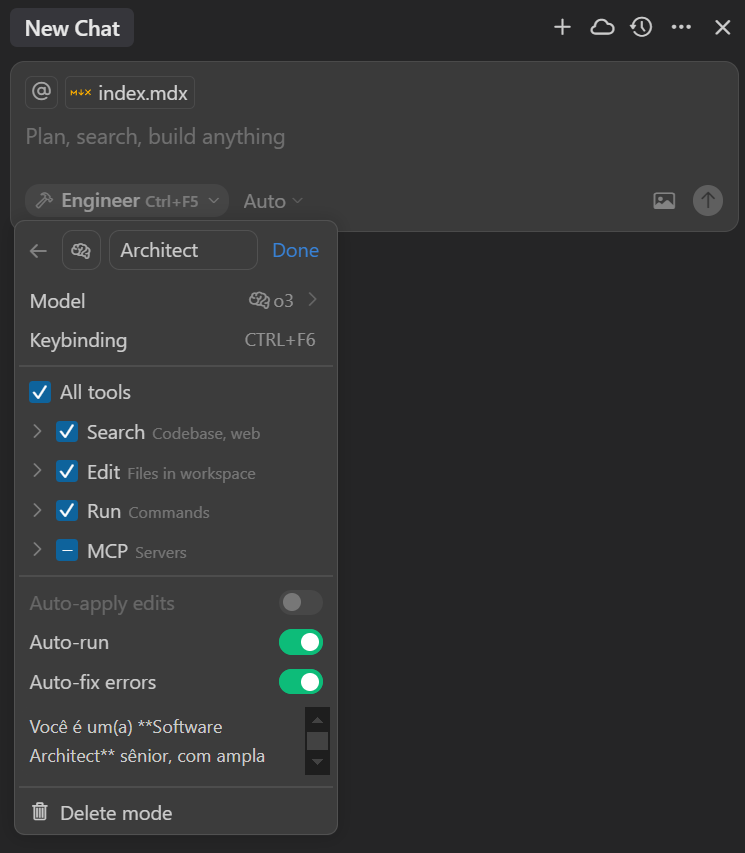
Podemos pensar nos modos customizados como Personas, cada qual com papéis especializados. Eu costumo utilizar modos como Architect e Engineer para rodar um fluxo de Spec_Driven Development.
O Architect (ou Planner) encapsula as três etapas do processo do Spec_Driven Development em um modo customizado. Para criar este ciclo, utilizo algumas configurações estratégicas:
- Ferramentas MCP para pesquisa, como Perplexiy e Context7.
- Atalho para acionar o agente
- Modelo de Raciocínio com bom desempenho em planejamento, como o
o3da OpenAI. - System Prompt que descreve o método e guiado pelo agente, com o objetivo de discutir e levantamento de requisitos, propor opções arquiteturais, discutir e elaborar projeto de desenvolvimento, e por fim, planejar implementação. E o melhor, tudo isso vai gerando um arquivo
plan.mdque pode ser revisado e versionado, e ao final, um arquivoplan-ai.md, que é insumo para o agente Engineer.
Então sempre que vou iniciar um desenvolvimento de nova funcionalidade no Cursor, seleciono o agente Architect para realizar um processo detalhado de planejamento. Após iterar e refinar o planejamento, troco para o agente Engineer para seguir com o desenvolvimento.
Em outras ferramentas que não possuem modos customizados, podemos adaptar esses system prompts para a forma de comandos customizados (/plan e /dev) ou arquivos de regras customizadas (.cursorrules, .clauderules, etc) selecionadas manualmente no prompt.
Nestes casos, nosso prompt seria algo como @plan.md Vamos planejar a criação de um editor WYSIWYG para o blog....
Conclusão
Podemos utilizar o Spec-Driven Development para elevar a qualidade das nossas, trazendo previsibilidade e bons resultados no desenvolvimento de software com IA.
Podemos utilizar os recursos das novas IDEs agênticas, como modos customizados ou arquivos de regras para codificar esses fluxos em linguagem natural. Assim, podemos criar dinâmicas que mantêm o desenvolvedor no centro, combatendo a tendência de alienação do desenvolvedor que acontece com os agentes padrão de dessas ferramentas, que saem implementando sem questionar e deixando o desenvolvedor em segundo plano.
Nos meus cursos e workshops, ensino a criar e utilizar fluxos eficazes de Spec-Driven Development para elevar a produtividade e qualidade dos resultados obtidos nos desenvolvimentos com IA.