
Como implementei a busca offline para o meu site estático feito em Hugo
Você já imaginou como seria implementar um sistema de busca totalmente off-line, sem servidor nenhum? Neste artigo eu mostro como implementei esse sistema para o meu blog usando Hugo e Lunr.js!
Este blog começou como um experimento e um objetivo: não custar nada no fim do mês.
Por isso decidi criar um site estático com um gerador chamado Hugo. Isso significa que não existe um backend para o blog; não existe uma arquitetura Cliente/Servidor, apenas o cliente, e todo o conteúdo do site é pré-renderizado.
Mas nem por isso ele precisa ser muito restrito em funcionalidades. Não é a falta de um servidor que impediria ter um recurso de busca de conteúdo no site.
A questão então era como implementar uma busca off-line para o blog.
Pesquisa
Após uma breve pesquisa encontrei uma página de documentação do Hugo descrevendo as principais estratégias para implementar um sistema de busca para um blog com Hugo.
Essas ferramentas variam bastante em complexidade e na abordagem para resolver o problema. Algumas geram o recurso de busca quase pronto, enquanto outras se limitam a gerar um arquivo de índice pesquisável por ferramentas especializadas.
Escolhi uma abordagem que julguei ser ao mesmo tempo flexível e que proporcionaria a maior quantidade de aprendizado.
Por isso, decidi usar uma ferramenta chamada Lunr.js (se lê ‘lunar’).
Lunr.js
Lunr.js é uma ferramenta que permite realizar buscas em índices previamente gerados. Ela ainda apresenta vários atributos interessantes:
- Não possui dependências
- Pode ser executada diretamente do navegador
- É extensível através de plugins
- Fácil de usar
A título de curiosidade, a ferramenta é inspirada em um projeto da Apache chamado Solr.
São necessários apenas três passos para fazer uma busca com o Lunr.js. O primeiro é criar um array de objetos contendo as informações pesquisáveis:
var posts = [{
"uri": "/posts/arquitetura-gritante",
"title": "Arquitetura Gritante",
"metadescription": "descrição para o Google",
"content": "Um dos meus capítulos preferidos do livro Arquitetura Limpa...",
"tags": ["arquitetura gritante", "arquitetura limpa", "SOLID", "SRP"]
}, {
"uri": "/posts/continuous-delivery-blog-com-hugo",
"title": "Entrega contínua de blogs Hugo com GitHub Actions",
"metadescription": "descrição para o Google",
"content": "O [Hugo](https://gohugo.io) é hoje um dos...",
"tags": ["hugo", "continuous delivery", "github actions"]
}, {
"uri": "/posts/pattern-matching-csharp",
"title": "Pattern matching no C# 8.0",
"metadescription": "descrição para o Google",
"content": "A partir do C# 7.0 a linguagem começou a receber...",
"tags": ["csharp", "pattern matching", "type matching"]
}];Com esses dados em mãos, podemos usar o Lunr.js para gerar um índice de busca:
var idx = lunr(function () {
this.ref('uri'); // esta é a informação identifica que identifica o post nos resultados
this.field('title');
this.field('content');
this.field('tags');
posts.forEach(function (doc) {
this.add(doc);
}, this);
});E com o índice gerado, é só questão de executar a busca:
var results = idx.search("pattern matching");Certo, mas se para gerar o índice, é necessário um array (em javascript) com as informações dos posts - que, aliás, o Hugo não gera -, então um primeiro passo é dar um jeito de gerar essas informações.
Seria necessário algum tipo de extrator: uma ferramenta que leia o conteúdo do blog e exporte um JSON com as informações necessárias dos posts.
É aí que entra o hugo-lunr.
Hugo Lunr
O Hugo-lunr é uma ferramenta feita em NodeJS que faz justamente isso: lê cada arquivo markdown (.md) abaixo de /content/posts e interpreta o arquivo a fim de gerar o dataset para a geração de índice do Lunr.js.
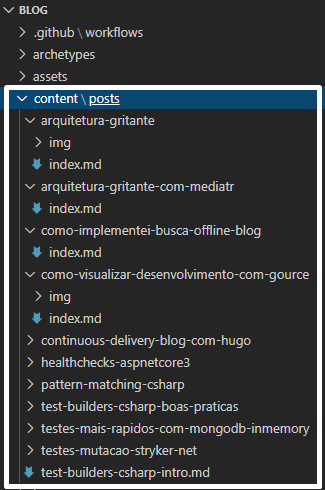
Para contextualizar, o conteúdo do blog é estruturado da seguinte forma:
O plano
Depois de estudar um pouco o Lunr.js e fazer um teste usando o Hugo-lunr fiquei convencido de que poderia obter um bom resultado com essa solução.
O plano então era implementar o seguinte:
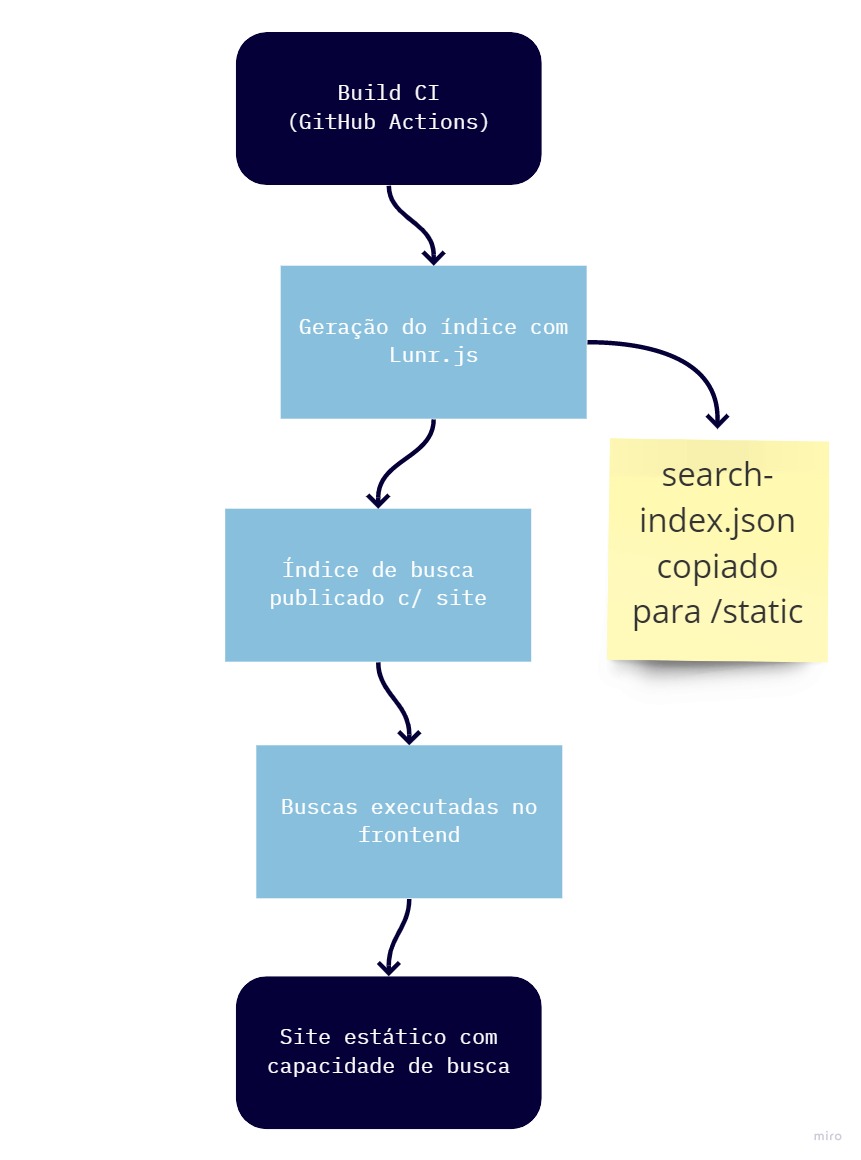
Era só uma questão de gerar os arquivos na pasta /static para o Hugo incluir automaticamente na publicação do site, e usá-los no javascript. Muito simples.
Mas é claro que haveria imprevistos.
Os desafios
O primeiro problema que tive foi com o Hugo-lunr, e em parte foi por conta da forma como eu organizei a publicação.
Para agendar um post, eu configuro uma data de publicação futura, e o processo de entrega contínua no GitHub Actions está configurado para rodar todos os dias às 8 horas da manhã. Por padrão. Como por padrão o Hugo não inclui posts com datas futuras, no dia que a data da postagem deixa de ser futuro, ela é automaticamente incluída no post. Mas até lá não.
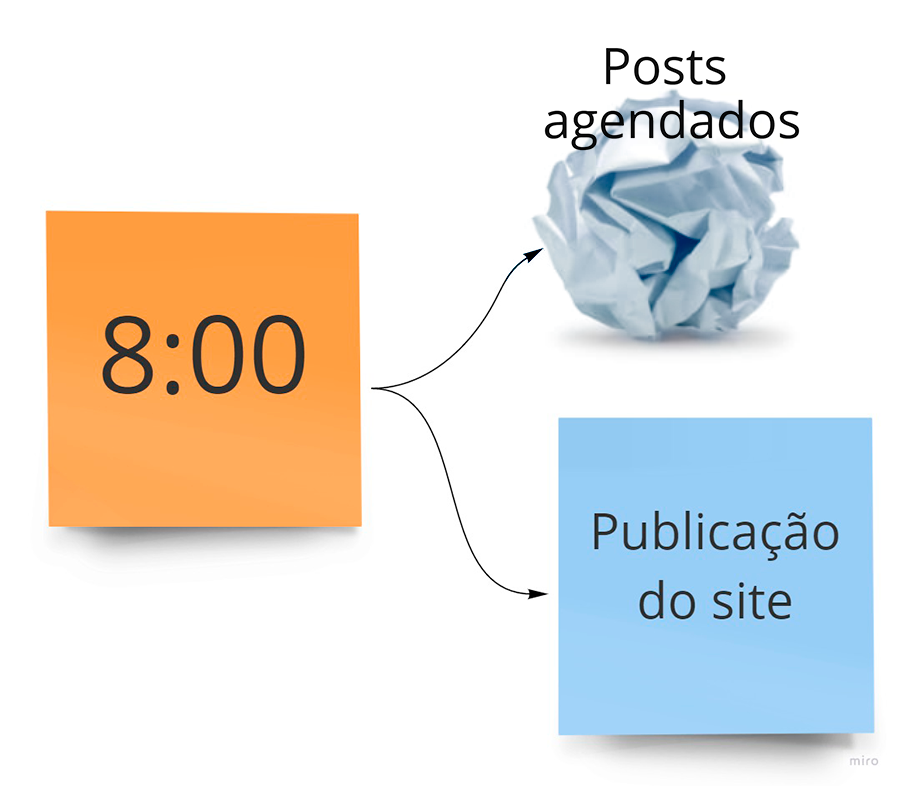
E o Hugo-lunr não suportava este comportamento.
Por isso precisei criar um fork do repositório. Criei um novo parâmetro para permitir filtrar posts futuros, além do filtro de rascunhos que já existia, e abri um Pull Request.
Só depois de uma semana percebi que o repositório estava abandonado, com pull requests sem resposta desde 2016. Não demorou para que aparecessem novas necessidades, então decidi seguir com o fork e modificá-lo conforme o necesssário.
Os metadados
Logo depois de ter publicado com sucesso a primeira versão do blog com o JSON de índice, comecei a implementação do tão sonhado sistema de busca.
Não demorou muito e descobri que faltava mais uma peça do quebra-cabeças: o arquivo do índice não preserva o conteúdo do dataset, então a única informação retornada era a uri do post. Infelizmente isso não era suficiente para gerar uma página de resultados. Eu precisava de metadados.
Então adicionei uma rotina para gerar um dataset menor para ser distribuído junto com índice. Este JSON é bastante semelhante ao dataset original, mas contendo apenas informações essencias para montar uma view minimamente decente:
var posts = [{
"uri": "/posts/arquitetura-gritante",
"title": "Arquitetura Gritante",
"metadescription": "Já ouviu falar em Arquitetura Gritante? Neste artigo exploramos o que torna gritante a arquitetura de uma aplicação, e como isso pode beneficiar um projeto de software."
}
// ...
];No fim, o script de geração dos arquivos ficou razoavelmente simples:
var fs = require('fs');
var lunr = require("lunr")
require("lunr-languages/lunr.stemmer.support")(lunr)
require("lunr-languages/lunr.pt")(lunr)
function createSearchIndex() {
// o arquivo search-data.json é o dataset gerado pelo meu fork do Hugo-lunr
fs.readFile('./search-data.json', 'utf8', function(err, data) {
if (err)
throw err;
// aqui é feita a geração do índice
const jsonData = JSON.parse(data)
const idx = lunr(function () {
this.use(lunr.pt)
this.ref('uri')
this.field('title', { 'boost': 1.5 })
this.field('tags', { 'boost': 1.2 })
this.field('content')
this.field('metadescription')
jsonData.forEach(doc => {
this.add(doc)
}, this)
})
// o índice é salvo em JSON para depois publicar junto com o site
const serializedIndex = JSON.stringify(idx)
fs.writeFile('./search-index.json', serializedIndex, 'utf-8', function(err) {
if (err)
throw err;
})
// o 'data companion' é basicamente um view model para construção da view de resultados
const dataCompanion = jsonData.map((doc) => {
return {
'uri': doc.uri,
'completeUri': `/posts${doc.uri}`.replace(/\/index$/, ""),
'title': doc.title,
'metadescription': doc.metadescription
};
})
// o 'data companion' também é salvo em JSON para depois publicar junto com o site
fs.writeFile('./search-data-companion.json', JSON.stringify(dataCompanion), 'utf-8', function(err) {
if (err)
throw err;
})
})
}O frontend
Depois de ter os arquivos sendo gerados, precisei implementar o frontend que iria consumir esses dados.
Criei um arquivo de Javascript com algumas funções auxiliares para carregar os dados e realizar buscas:
function loadSearchData() {
return fetch('/search-data-companion.json')
.then(response => response.json())
.then(data => {
window.searchData = data;
return data;
});
}
function loadSearchIndex() {
return fetch('/search-index.json')
.then(response => response.json())
.then(data => {
window.searchIndex = lunr.Index.load(data);
return window.searchIndex;
});
}
function performSearch(query) {
if (!window.searchIndex) {
console.error('Search index not loaded');
return [];
}
const results = window.searchIndex.search(query);
return results.map(result => {
const post = window.searchData.find(post => post.uri === result.ref);
return {
...post,
score: result.score
};
});
}E também criei uma interface simples para busca:
function initializeSearch() {
const searchInput = document.getElementById('search-input');
const searchResults = document.getElementById('search-results');
searchInput.addEventListener('input', function(e) {
const query = e.target.value.trim();
if (query.length < 2) {
searchResults.innerHTML = '';
return;
}
const results = performSearch(query);
displayResults(results, searchResults);
});
}
function displayResults(results, container) {
if (results.length === 0) {
container.innerHTML = '<p>Nenhum resultado encontrado.</p>';
return;
}
const html = results.map(result => `
<div class="search-result">
<h3><a href="${result.completeUri}">${result.title}</a></h3>
<p>${result.metadescription}</p>
</div>
`).join('');
container.innerHTML = html;
}O resultado
O resultado final foi um sistema de busca completamente offline, que funciona muito bem para o tamanho do blog. A busca é rápida e os resultados são relevantes.
Algumas melhorias que implementei posteriormente:
- Suporte a português: Adicionei o plugin
lunr-languagespara melhorar a busca em português - Boost de campos: Dei mais peso para títulos e tags nos resultados
- Debounce: Adicionei um pequeno delay para evitar muitas buscas enquanto o usuário digita
- Highlight: Implementei destaque dos termos encontrados nos resultados
O sistema todo funciona sem necessidade de servidor, é rápido e proporciona uma boa experiência de busca para os visitantes do blog.
Conclusão
Implementar um sistema de busca offline para um site estático não é tão complicado quanto parece. Com as ferramentas certas (Hugo, Lunr.js e um pouco de JavaScript), é possível criar uma funcionalidade robusta e eficiente.
O maior desafio foi entender como integrar todas as peças, mas uma vez que o sistema está funcionando, a manutenção é mínima. Toda vez que publico um novo post, o índice é automaticamente atualizado durante o processo de build.
Esta solução pode ser adaptada para outros geradores de sites estáticos e é uma excelente alternativa para quem quer adicionar busca sem depender de serviços externos ou backends complexos.