
Testes de mutação com Stryker.NET
Aprenda a usar testes de mutação para avaliar a qualidade de uma suíte de testes. Neste artigo, mostro como usar o Stryker para melhorar os testes de aplicações C#.
A realidade do desenvolvimento nos dias atuais demanda agir rápido. Nossos produtos precisam ser capazes de mudar quase tão rapidamente quanto o comportamento e as demandas dos nossos clientes. Precisamos ser capazes de correr. De entregar rápido e errar rápido. De aprender com os erros e seguir em frente. E a única forma segura de seguir em frente num ritmo alucinante é seguir com qualidade.
Os testes unitários são uma das principais ferramentas do desenvolvedor para garantir um desenvolvimento com qualidade. Se bem implementados, nos dão a segurança necessária para seguir com modificações importantes sem medo de quebrar outras partes do software.
Em certos tipos de projetos, precisamos de uma forma de avaliar se nossas suítes de testes são suficientes. Queremos um número, um indicador de que o time está escrevendo testes consistentemente. Então usamos ferramentas de análise de cobertura de código.
E então essas nos dão um o desejado número mágico: o Percentual de Cobertura de Código. O time define uma meta: 70% de cobertura até o fim do ano. Um time mais audacioso que trabalha num projeto open-source pode chegar à conclusão de que precisam manter o percentual em 100%.
Mas algumas vezes, esses mesmos times percebem que apesar de terem 80 ou 90% de cobertura, o software deixa a desejar no quesito de qualidade, e está cheio de bugs. Às vezes, eles percebem que o número é uma ilusão, e que o percentual de cobertura não é indicativo assertivo de qualidade.
O problema dos testes de cobertura de código
Para entender este problema, precisamos olhar atentamente para o quê a análise de cobertura de código de fato analisa.
Tomemos por exemplo a seguinte função, que identifica se uma pessoa está na faixa de risco de uma doença com base na sua idade:
public bool FaixaRisco(int idade)
{
if (idade >= 18 && idade < 35)
return true;
else
return false;
}Como podemos ver no exemplo acima, é uma função muito simples, que identifica pessoas entre 18 e 35 anos como estando na faixa de risco.
Imaginemos que o desenvolvedor que implementou esta rotina escrever os seguintes testes:
[Fact]
public void Deve_identificar_que_a_pessoa_esta_na_faixa_de_risco()
{
FaixaRisco(idade: 20).Should().BeTrue();
}
[Fact]
public void Deve_identificar_que_a_pessoa_esta_fora_da_faixa_de_risco()
{
FaixaRisco(idade: 15).Should().BeFalse();
}Os testes estão passando e ele manda o código para frente. Talvez o seu pull request seja aprovado e o branch é integrado no master. O build funcionou, os testes passaram, e a cobertura de código da sua rotina foi de 100%, o que pode gerar um sentimento de segurança, já que a qualidade deve estar alta.
O percentual de cobertura chegou a 100% por conta do critério utilizado para o cálculo da cobertura. Ele se baseia no percentual de branches executados a partir da suíte de testes.
if (idade >= 18 && idade < 35)
return true; // branch 1: passou por aqui no teste com idade *20*
else
return false; // branch 2: passou por aqui no teste com idade *15*Existem outros subtipos de cobertura de código, como a cobertura de funções, de laços e de instruções, mas todas elas nos teriam trazido a 100% no caso específico do exemplo acima.
Já podemos começar a ver por que essa estratégia de avaliação não é indicativa de corretude do código. Ela garante apenas que existem testes que testam certos trechos de código. A qualidade destes testes não é avaliada.
Não muito depois de o código ir para produção, o time identifica que pessoas com 35 anos sendo excluídos da faixa de risco. Eles revêem a regra de negócio com o Analista de Negócios, e ela era clara: Devem ser considerados na faixa de risco pessoas com idade de 18 anos a 35 anos. Temos um bug.
Neste ponto, deve estar claro que um percentual alto de cobertura de código garante que nossos testes executam o código e testam certas combinações de cenários.
O que eles não garantem, é que os cenários corretos estão sendo testados. Às vezes, nossas suítes de testes são pobres, e estão cheias de testes que não garantem muita coisa. Mas como podemos testar a qualidade de uma suíte de testes?
É aí que entram os testes de mutação.
Testes de mutação
Os testes de mutação estão por aí há bastante tempo. O conceito surgiu no final dos anos 1970, só que até alguns anos atrás, o foco era quase inteiramente acadêmico. Mas hoje em dia existem ferramentas consistentes para a maioria das grandes linguagens de programação.
Mas o que são esses tais testes de mutação? E como funcionam?
Para responder essas perguntas, primeiro precisamos conhecer duas hipóteses, sobre as quais o conceito dos testes de mutação é construído.
A primeira é a Hipótese do Programador Competente, segundo a maior parte das falhas introduzidas por um programador experiente se devem a pequenas erros sintáticos.
A segunda delas é a Hipótese do Efeito de Acoplamento. De acordo com ela, falhas simples, como as descritas pela hipótese anterior, podem cascatear ou se acoplar, gerando novos erros.
Assim, por associação, podemos concluir que erros complexos são formados através de uma conjunção de erros simples através do Efeito de Acoplamento. E é na detecção destes pequenos erros sintáticos que os testes de mutação atuam.
A ideia geral é bem simples: a ferrementa utiliza um processo chamado mutator para introduzir um erro sintático no código, gerando um mutante, ou seja, uma variação defeituosa do código original. Ela repete esse processo várias vezes, gerando vários mutantes, cada qual com sua única alteração.
Um mutante pode ser algo tão simples quanto a troca de operador lógico:
if (a == b)
return;
// pode virar
if (a != b)
return;Temos assim uma coleção de mutantes. Na sequência, para cada mutante gerado, a ferramenta roda a nossa suíte de testes e avalia os resultados.
A lógica aplicada é bem simples: se algum teste falhou, o mutante foi morto e não precisamos nos preocupar com ele. Agora, se nenhum teste falhou, então o mutante sobreviveu.
O diagrama a seguir pode ajudar a visualizar este processo:
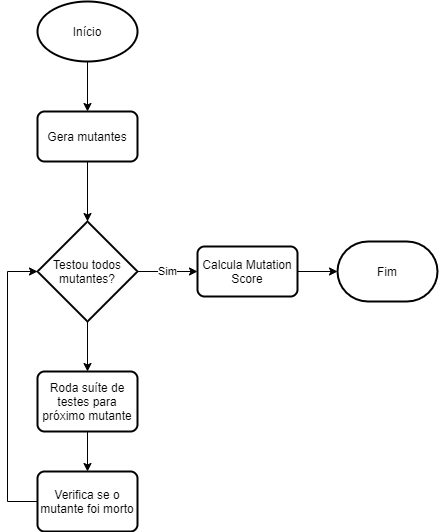
Ao final do processo, a ferramenta vai gerar um relatório detalhando quais mutantes foram mortos e quais sobreviveram. Este relatório vai incluir uma métrica muito importante: a Mutation Score.
Mutation Score
Com base na relação de mutantes mortos e sobreviventes, a métrica é calculada segundo a seguinte fórmula:
Mutation Score = Mutantes mortos / Total de mutantes
Assim, se matarmos oito de dez mutantes, teremos uma pontuação de 80%.
Vale notar que existem alguns estudos que apontam uma correlação entre as falhas identificadas pelos testes de mutação e falhas reais, mas poucos se baseiam em números realmente grandes de programas reais para provar que a correlação é mesmo significativa. Ainda assim, estes testes podem nos ajudar muito mais do que a cobertura de código.
Mutators
Como vimos brevemente acima, um mutator é um processo responsável por gerar uma mutação sintática específica no código alvo, e podem ser dos mais variados tipos, variando por ferramenta e linguagem de programação.
A título de exemplo, vou listar a seguir algumas alterações que a ferramenta Stryker pode realizar em programas C# no .NET Core:
| Original | Mutado |
|---|---|
| a + b | a - b |
| new Array(1, 2, 3, 4) | new Array() |
| *= | /= |
| true | false |
| while (a > b) | while (false) |
| “John Doe" | "" |
| a++ | a— |
| a == b | a != b |
| a && b | a |
| OrderBy() | |
| Max() | Min() |
Say() { Print('Hi!') } | Say() {} |
| "" | "Stryker was here!” |
| -a | +a |
Existem muitos outros mutators disponíveis, mas já é o suficiente para termos uma ideia de que tipo de mutantes serão gerados.
Exemplo prático
Vamos voltar ao exemplo anterior e ver como os testes de mutação poderiam ajudar. Na versão abaixo, o tal bug que excluia da faixa as pessoas com 35 anos já foi corrigido:
public bool FaixaRisco(int idade)
{
if (idade >= 18 && idade <= 35) // corrigida operador de "<" para "<="
return true;
else
return false;
}Mas infelizmente a suíte de testes não mudou:
[Fact]
public void Deve_identificar_que_a_pessoa_esta_na_faixa_de_risco()
{
FaixaRisco(idade: 20).Should().BeTrue();
}
[Fact]
public void Deve_identificar_que_a_pessoa_esta_fora_da_faixa_de_risco()
{
FaixaRisco(idade: 15).Should().BeFalse();
}Sempre que precisamos testar uma faixa de valores, precisamos focar em exercitar os limites desta faixa. Isso vale para faixas de data, de valores ou qualquer outra que tem inicio e fim.
Então alguém do time configura uma ferramenta de testes de mutação, e o relatório indica que um dos três mutantes gerados foram mortos (na realidade, seriam muitos mais mutantes, mas estamos tentando manter as coisas simples aqui).
Digamos que tenham sido gerados estes três mutantes:
// ORIGINAL (PARA COMPARAÇÃO)
public bool FaixaRisco(int idade)
{
if (idade >= 18 && idade <= 35)
return true;
else
return false;
}
// MUTANTE 1
public bool FaixaRisco(int idade)
{
if (idade < 18 && idade <= 35)
return true;
else
return false;
}
// MUTANTE 2
public bool FaixaRisco(int idade)
{
if (idade >= 18 && idade < 35)
return true;
else
return false;
}
// MUTANTE 3
public bool FaixaRisco(int idade)
{
if (idade > 18 && idade < 35)
return true;
else
return false;
}O time roda os testes de mutação, e descobre que apenas o mutante 1 foi morto. Os outros dois continuam vivos para assombrar o time.
O acontece é que ao testar o “Mutante 1” com a condição idade < 18 && idade <= 35 usando o valor 15, um dos testes esperava que a rotina retornasse que está fora da faixa, mas o mutante mudou o comportamento. Ou seja, o desenvolvedor acertou pelo menos uma coisa ao escrever os testes: ele garantiu que valores abaixo da faixa estão fora.
Já os outros mutantes não foram mortos, porque não havia testes validando os valores nos limites da faixa de risco, e este é um dos cenários em que os testes de mutação podem indicar quais testes estão faltando na nossa suíte.
Vamos então rever a regra de negócio e identificar qual é o mínimo de cenários de teste necessário para garantir o comportamento correto desta rotina:
“Devem ser considerados na faixa de risco pessoas com idade de 18 anos a 35 anos.”
Como podemos ver, para garantir a corretude desta rotina, vamos precisar de 4 testes, validando os valores nos limites da faixa:
- 17 está fora da faixa
- 18 está dentro da faixa
- 35 está dentro da faixa
- 36 está fora da faixa
No caso da rotina acima, a seguinte suíte de testes teria matado todos os mutantes possíveis:
[Theory]
[InlineData(18)]
[InlineData(25)]
[InlineData(35)]
public void Deve_identificar_que_a_pessoa_esta_na_faixa_de_risco(int idade)
{
FaixaRisco(idade).Should().BeTrue();
}
[Theory]
[InlineData(17)]
[InlineData(36)]
public void Deve_identificar_que_a_pessoa_esta_fora_da_faixa_de_risco(int idade)
{
FaixaRisco(idade).Should().BeFalse();
}Como vimos, ao observar quais mutantes sobrevivem, podemos identificar buracos na nossa suíte de teste. Alguns destes buracos podem ser fontes de falhas.
Performance dos testes de mutação
Temos um detalhe importante para considerar quando configurarmos testes de mutação: a performance. Conforme mencionado mais acima, a suíte de testes roda uma vez para cada mutante gerado.
Dependendo do tamanho e da característica dos testes da nossa suíte, rodá-los centenas de vezes pode ser bastante demorado. Em alguns casos, pode levar horas ou até dias.
Para mitigar esse problema, cada ferramenta dispõe de mecanismos próprios para acelerar os testes. Algumas permitem paralelizar a execução dos testes ou outros artifícios, mas todas elas permitem restringir o escopo dos testes.
Normalmente podemos restringir a geração de mutantes para certas classes, namespaces ou pacotes que necessitam de maior atenção. Podem ser rotinas críticas ou o core de uma aplicação.
Outra opção, é rodar os testes de mutação de forma mais abrangente de forma agendada, à noite ou de madrugada.
Ferramentas
Existem várias ferramentas disponíveis. Algumas das principais são:
| Ferramenta | Tecnologias |
|---|---|
| Stryker | JavaScript, TypeScript, C# e Scala |
| mutmut | Python |
| Cosmic Ray | Python |
| PIT | Java |
| Infection | PHP |
Na sequência vamos dar uma olhada em como rodar os testes de mutação com Stryker para o exemplo acima.
Stryker .NET
Para instalar globalmente o Stryker para .NET Core, basta rodar:
dotnet tool install -g dotnet-strykerA forma mais prática de configurar a ferramenta, é criar um arquivo de configuração stryker-config.json na raiz do projeto de testes, como este:
{
"stryker-config":
{
"test-runner": "vstest",
"reporters": [ "progress", "html", "json"],
"log-level": "info",
"timeout-ms": 15000,
"log-file": true,
"project-file": "RiscDetection.csproj",
"max-concurrent-test-runners": 4,
"threshold-high": 90,
"threshold-low": 70,
"threshold-break": 0,
"mutate": [
"**/FaixaEtaria*.cs"
],
"files-to-exclude": [],
"excluded-mutations": [],
"ignore-methods": ["ToString", "LogInformation", "LogError", "Append"]
}
}No exemplo acima, podemos ver algumas configurações úteis:
- Podemos escolher o test runner mais adequado com
test-runner - Temos vários reporters à disposição com
reporters - Podemos especificar quais fontes mutar com
mutate - Podemos ignorar métodos para geração de mutantes com
ignore-methods - Podemos excluir certos mutators com
excluded-mutations
Um detalhe importante é que o campo project-file deve ser o arquivo de um projeto referenciado pelo projeto de testes.
Enfim, uma vale a pena dar uma olhada atenta à documentação do projeto, pois ele está cheio de opções interessantes.
Feito isso, basta executar o comando dotnet-stryker a partir da raiz do projeto de testes.
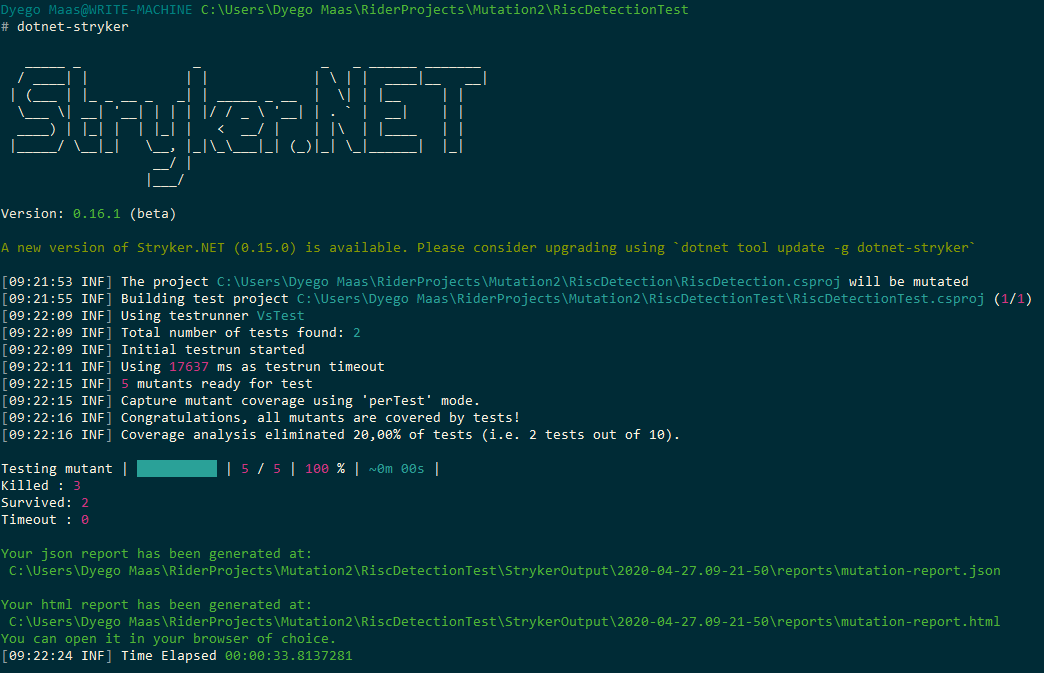
Como podemos ver na imagem acima, como três reporters, obtivemos três saídas. Primeiro, o relatório de progresso no próprio console. E depois, um relatório em formato JSON e outro no formato HTML.
O relatório JSON pode ser útil para processamento por outras ferramentas ou até para criação de views customizadas.
Mas é no relatório HTML que encontramos maior insight.
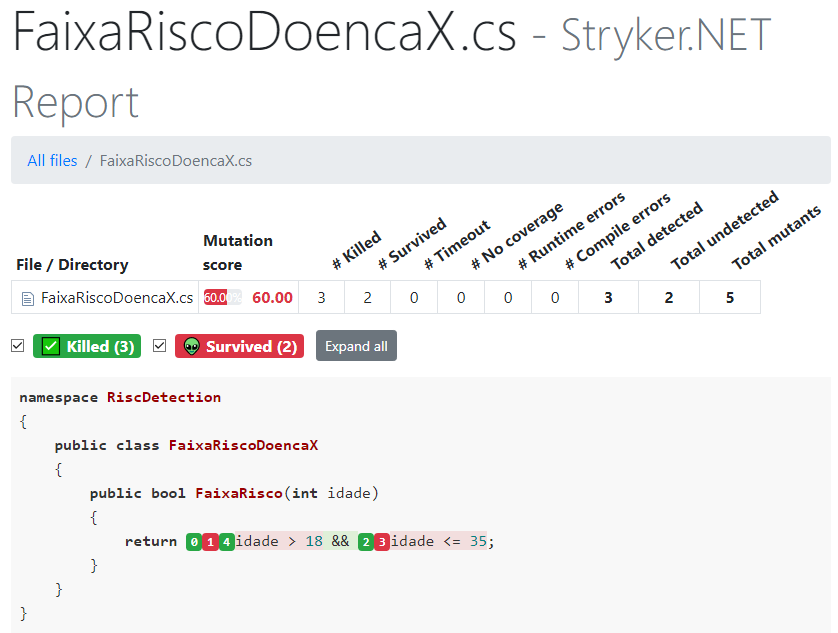
Podemos ver quais mutantes foram mortos:
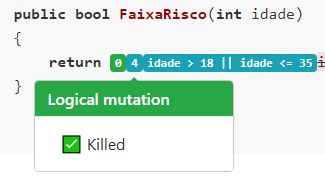
Mas o mais importante, são os mutantes sobreviventes, pois eles são indicativos de testes que estão faltando na nossa suíte. E como podemos ver, são justamente os cenários nos limites das faixas, aqueles pontos que segundo a Hipótese do Programador Competente têm a maior probablidade de concentrar os pequenos problemas que levam a falhas nos nossos softwares.
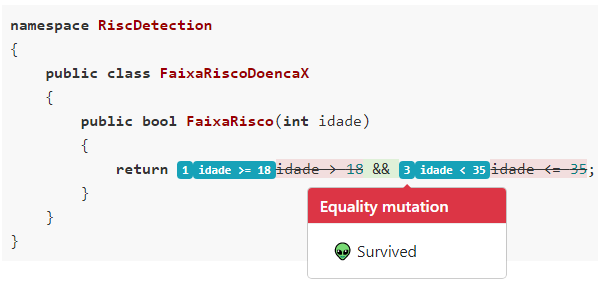
Como vimos neste artigo, os testes de mutação podem ter um papel muito importante tanto para avaliar a qualidade das nossas suítes de teste quanto durante o desenvolvimento, para guiar o desenvolvedor na elaboração de novos cenários.
Os exemplos acima são super simples, mas em projetos reais, a quantidade de combinações de cenários pode crescer de forma explosiva, e os testes de mutação podem ser nossos aliados para entregar com mais qualidade.
O código do exemplo acima está disponível num repositório do GitHub.