
Code Coverage garante qualidade?
Code Coverage é uma métrica útil? Vale a pena buscar 100% de cobertura? Alta cobertura de código garante qualidade? Neste artigo exploro essas e outras questões.
Code coverage (cobertura de código) é o percentual de código que está coberto por testes automatizados. Essa métrica é medida em todo código que é executado quando os testes rodam. Ela pode nos dar um feedback poderoso, mas também tem suas fragilidades.
Neste artigo, vamos explorar vários aspectos do Code Coverage, veremos como melhor aplicá-la para obter bons resultados, e também um pouco sobre métricas complementares que ajudam a ganhar confiança nos números obtidos.
Como a métrica Code Coverage é calculada?
A maioria das ferramentas modernas de análise de cobertura se baseiam em instrumentação de código. Ou seja, analisam as estruturas do código (classes, métodos, declarações, branches).
Existem três tipos de análise de cobertura que essas ferramentas geralmente vão realizar:
| Tipo | Descrição |
|---|---|
| Statements (declarações/comandos) | Statement coverage mede se cada Statement foi executado durante os testes. |
| Branches (ramificações) | Branch coverage mede se possíveis ramificações nas estruturas de fluxo de controle foram seguidas. Por exemplo, se entrou em cada if/else, ternários, cada opção de switch/case. |
| Methods (métodos) | Method coverage mede se um método chegou a ser executado durante os testes. |
Quando uma ferramenta de cobertura de código roda, ela realiza essas três análises e as utiliza para gerar uma métrica composta, que é o Percentual Total de Cobertura. Este é o valor apresentado pelas ferramentas.
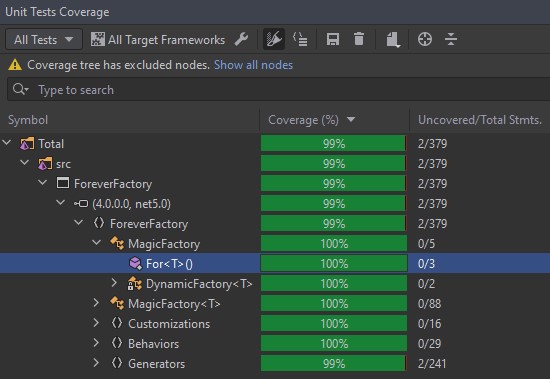
Nota
Algumas ferramentas, como Cobertura ou Emma geram uma métrica chamada Line Coverage. Esse é uma métrica bem simples que mede o número de linhas de código cobertas pelos testes. É oferecida por ferramentas que fazem instrumentação de bytecode. Como elas só tem acesso às classes compiladas, só tem acesso ao número da linha. A métrica Statement Coverage é bem semelhante, mas com a vantagem de trazer mais informação útil.
Quando Code Coverage é útil?
Code Coverage é uma métrica importante como parte de um ciclo de feedback no processo de desenvolvimento de software. Os relatórios de cobertura são fundamentais para entender quais partes de um software estão mais cobertas por testes, e quais estão mais vulneráveis. Então podemos concluir que é sempre útil acompanhar essa métrica.
O grau de utilidade da métrica e dos relatórios de cobertura vai depender da nossa capacidade de utilizar essa informação a fim ajudar na tomada de decisões no projeto, e pode variar com base no contexto de cada projeto.
Por exemplo, um time que está começando a adotar testes automatizados num projeto legado pode utilizar essa métrica para acompanhar o progresso dos esforços na adoção de práticas de teste, focando num primeiro momento em atingir um percentual de moderado de cobertura, e focando mais em cobrir rótinas críticas específicas.
Já um time maduro na escrita de testes automatizados e que mantém um percentual de cobertura razoavelmente alto no seu projeto, pode utilizá-la para garantir que a suíte de testes continua testando bem a aplicação à medida que ela evolui.
A análise de cobertura deve ser executada junto com os testes, de forma automatizada, no pipeline de CI do projeto. Desta forma, teremos feedback rápido sobre a evolução dos testes e do projeto. Se o percentual de cobertura diminuir abaixo de um número pré-determinado, podemos inclusivo fazer o build falhar, exigindo que o time escreva mais testes.
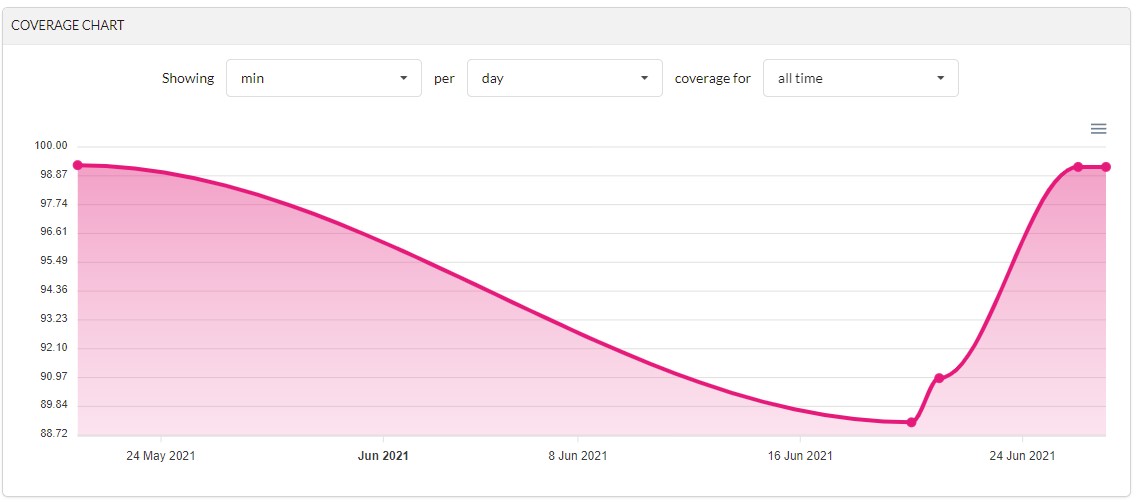
Quando faz sentido mirar 100% de cobertura?
Cobertura de código costuma seguir a regra do 80-20, ou seja, quanto mais nos aproximamos dos 100% de cobertura, mais difícil se torna aumentar a cobertura. Isso ocorre porque muitas vezes alguns testes básicos conseguem cobrir grande parte do fluxo. Mas para avançar mais adiante na cobertura, serão necessários testes cada vez mais específicos para tratar pequenos cenários alternativos.
Projetos de código aberto (open-source) costumam mirar coberturas de 100% ou bem próximas disso. Isso é importante, porque dezenas ou até milhares de outros aplicações podem depender desse projeto. Então esta é uma situação em que faz bastante sentido mirar números bem altos de cobertura.
Para projetos comerciais de código fechado, creio que exceto raras exceções de alta criticidade, não é necessário um índice de cobertura tão alto para colher frutos. Na Google há um guideline geral de 60% como “aceitável”, “75%” como recomendável, e 90% como “exemplar”. Minha recomendação nesses casos é mirar 80% de cobertura quando possível.
Metas irrealistas
Deve-se tomar muito cuidado ao definir metas para a Cobertura de Código num projeto de software, especialmente se estiverem atreladas a algum tipo de bônus. Metas pouco realistas podem levar a um atingimento falso da meta. Um exemplo de meta pouco realista é atingir 80% de cobertura em seis meses num grande sistema legado com um time que não tem experiência prévia com testes.
E como é possível atingir a meta sem atingi-la? A resposta é simples: com testes falsos. Abaixo, temos um exemplo que gera 100% de cobertura sem testar nada.
Falsa Cobertura de Código
Teste que gera 100% de cobertura para o método CalcularJurosSimples, sem testar nada
public class CalcularJurosSimples(float capitalInicial, float taxaJuros, int tempo)
{
return capitalInicial * (1 + taxaJuros * tempo);
}
[Fact]
public void Deve_calcular_juros_compostos()
{
var montante = CalcularJurosSimples(1000f, 0.1f, 12);
// montante.Should().Be(); // <1>
}- Note que nesse caso, a asserção do teste nem chegou a ser implementada. Mesmo sem testar nada, como o método
CalcularJurosSimplesé invocado durante o teste, o relatório de cobertura vai indicar que está devidamente coberto.
Dica
Infelizmente, esse tipo de coisa acontece por aí, e implica que atingir um alto percentual de cobertura de testes não significa ter bons testes. Isso implica que atingir um alto percentual de cobertura de testes não significa ter bons testes.
E como saber se nossa suíte de testes está boa? Para ganhar confiança e garantir que ela testa de fato o que precisa ser testado, podemos usar uma contra-métrica chamada Mutation Score, que veremos na próxima seção.
Mutation Score
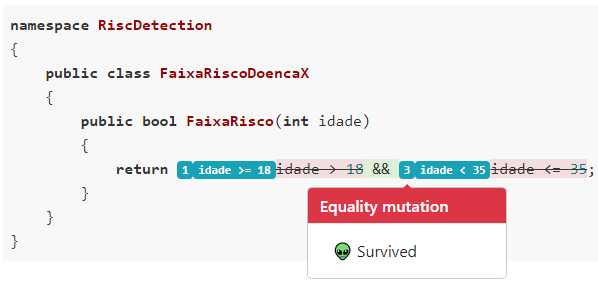
Mutation Score (ou Escore de Mutação) é uma métrica gerada por ferramentas de Teste de Mutação. O objetivo dos Testes de Mutação é medir a habilidade de uma suíte de testes identificar problemas no código. Ela considera que uma boa suíte de testes deve ser capaz de identificar erros introduzidos no código.
E como essas ferramentas funcionam? Elas introduzem erros no código da aplicação, e rodam os testes para ver se eles identificam essas mutações. Idealmente, para cada mutação introduzida, pelo menos um teste deveria quebrar. Se nenhum teste quebrar, significa que a suíte de testes tem pontos cegos, e precisa de mais testes.
Um bom Mutation Score, aliado a um Percentual de Cobertura razoável formam um excelente par de contra-métricas que nos ajudam a atingir qualidade no código e nos testes.
Se você quiser conhecer mais sobre testes de mutação, confira meu outro artigo, onde falo em detalhes sobre como introduzir testes de mutação em projetos .NET com a ferramenta Stryker.NET.
Resumo
- 100% de cobertura de código faz sentido em projetos open-source
- 80% de cobertura de código é suficiente para a maioria dos projetos comerciais
- Alto percentual de cobertura de testes não garante qualidade
- Testes de Mutação podem complementar a Cobertura de Código, para garantir a qualidade da suíte de testes e da aplicação
Podcast
Também tive a oportunidade de discutir sobre esses tópicos no AmbevTech Talk.