
Como criar um gerador de microserviços usando o Replicante
Quer saber uma forma simples de criar um gerador de microserviços? Neste artigo eu mostro como usar a ferramenta Replicante para isso.
Em cada organização, há uma estratégia diferente para agilizar a criação de novos microserviços. O espectro é bem amplo, indo de padronização global até a liberadade total.
Em muitos lugares, a estratégia da estrada pavimentada ainda não é uma realidade, e não há geradores de serviços, nem muitas bibliotecas prontas para facilitar muitas das situações do dia-a-dia. Mas existem formas de agilizar a criação de novos microserviços que não exigem tanto esforço e podem ser implementadas rapidamente.
Uma delas, é criar seu próprio gerador de microserviços. E a parte mais importante é, um gerador de serviços não precisa ser complicado! Neste artigo, vou mostrar como utilizar uma ferramenta de código aberto para criar o seu.
Nossa estratégia é simples: nosso gerador vai aplicar algumas transformações a um template, e assim gerar o novo serviço.
Criando um gerador de microserviços
O primeiro passo para fazer um gerador de serviços, é ter um modelo de serviço a seguir. Afinal, precisamos de um ponto de partida. Para montar esse modelo, será necessário tomar algumas decisões.
Essas decisões envolvem questões arquiteturais, expertise do time, escolha da arquitetura de aplicação, tecnologias envolvidas, entre outros.
A título de exemplo, nosso serviço modelo terá as seguintes características:
- Plataforma: C#/.NET 5
- Arquitetura de aplicação: em camadas, no modelo Clean Architecture
- Banco de dados padrão: MongoDB
- Message broker padrão: RabbitMQ
- Testes de unidade, integração e mutação
Assim, criamos um serviço chamado TemplateCleanArchitecture, que implementa a versão ideal do conjunto de características da lista acima. Costumo dizer que ele não é apenas um exemplo de serviço, mas um serviço exemplar.
E qual é a nossa estratégia para um gerador? Não poderia ser mais simples: copiar nosso serviço exemplar, aplicando pequenas transformações. Foi para isso que o Replicante foi criado.
Replicando um serviço
Tenho um artigo aqui no blog dedicado à criação do Replicante, que você pode conferir aqui. Em termos gerais, o Replicante processa uma cópia de projeto aplicando duas fases de transformação:
- Substituição de termos na estrutura de diretórios (nomes de arquivos e pastas)
- Substituições do conteúdo de arquivos
Se quisermos reutilizar um serviço C#, temos que tomar alguns cuidados:
- Renomear namespaces dentro dos arquivos fonte e de projeto
- Ajustar termos nos arquivos de configuração, pipelines, Dockerfiles, etc.
- Renomear diretórios para refletir a nova estrutura de namespaces
Fazer isso manualmente está sujeito a muitos erros, e o Replicante permite fazer todas essas etapas num único passo. Para fins de exemplo, veja a pipeline do Azure DevOps mais abaixo, que usa a CLI do Replicante para gerar um novo serviço com base no template e numa receita:
name: '1.0.0'
parameters:
- name: 'ServiceName'
type: 'string'
displayName: 'Nome do serviço'
variables:
- name: 'TemplateWorkingDirectory'
value: '$(System.DefaultWorkingDirectory)/Services/CleanArchitectureTemplate'
stages:
- stage: 'GenerateNewCSharpService'
displayName: 'Generate new CSharp service'
jobs:
- job: 'GenerateNewCSharpServiceJob'
steps:
- task: NodeTool@0
displayName: 'Using Node'
inputs:
versionSpec: '14.16'
- script: |
npm install -g replicante@1.1.1
sed -i 's/%ReplicantName%/${{ parameters.ServiceName }}/g' replicante-recipe.json
replicante create $(TemplateWorkingDirectory) replicante-recipe.json --target=$(Build.ArtifactStagingDirectory)
displayName: 'Replicating template service'
- task: PublishPipelineArtifact@1
displayName: 'Publish pipeline artifact'
inputs:
artifactName: '${{ parameters.ServiceName }}'
targetPath: '$(Build.ArtifactStagingDirectory)'Ao rodar este pipeline, precisamos informar o nome do nosso serviço, que vai definir o valor do parâmetro ServiceName. No exemplo da imagem, definimos que nosso novo serviço será o MeuNovoServico:
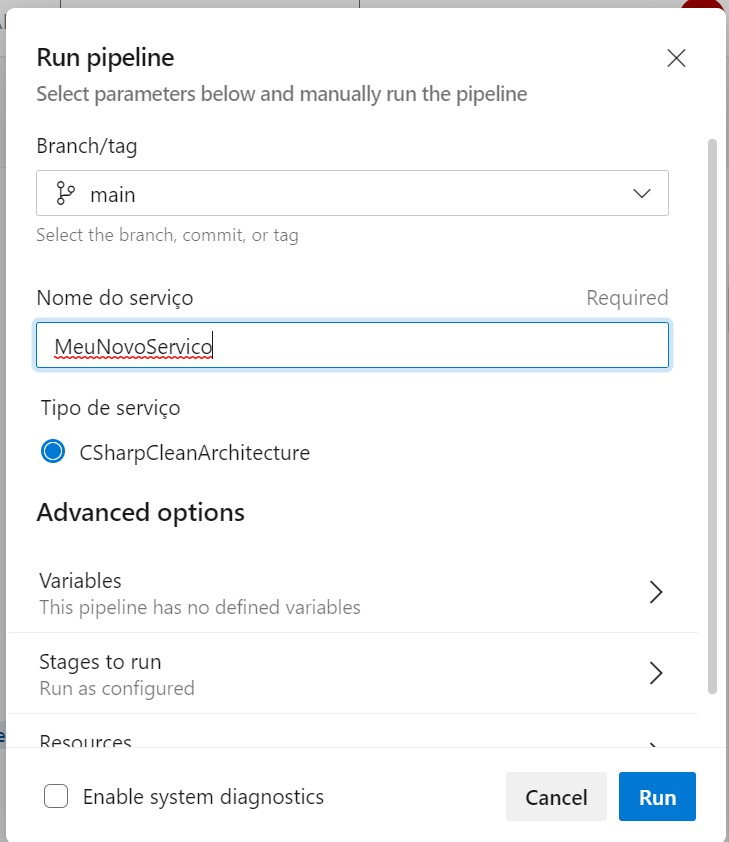
Como podemos ver no script, usamos o comando sed para substituir o termo %ReplicantName% pelo valor de ServiceName dentro do arquivo replicante-recipe.json. Este arquivo é importante, e centraliza nossa estratégia de transformação do serviço exemplar no novo serviço MeuNovoServico:
{
"replicantName": "%ReplicantName%",
"templateName": "clean-ms-gen",
"fileNameReplacements": [
{ "from": "TemplateCleanArchitecture", "to": "<<: replicantName :>>" },
{ "from": "templatecleanarchitecture", "to": "<<: replicantName.toLowerCase() :>>" }
],
"sourceCodeReplacements": [
{ "from": "TemplateCleanArchitecture", "to": "<<: replicantName :>>" },
{ "from": "templatecleanarchitecture", "to": "<<: replicantName.toLowerCase() :>>" },
{ "from": "TEMPLATECLEANARCHITECTURE", "to": "<<: replicant.toUpperCase() :>>" }
],
"ignoreArtifacts": [".git", ".idea", ".vs", ".vscode", "docs", "bin", "obj"]
}Como podemos ver acima, as instruções na seção fileNameReplacements correspondem à primeira etapa, onde certos termos serão substituídos por novos, alterando nomes de arquivos e pastas.
A mesma lógica se aplica à seção sourceCodeReplacements, que indica as substituições que serão feitas nos conteúdos dos arquivos, alterando namespaces, arquivos de configuração, pipelines, entre outros.
Na sequência, o script roda executa a CLI do Replicante informando três parâmetros:
- O arquivo da receita de transformação
- O diretório do template, onde está o serviço exemplar
- O diretório de saída, onde será gerado nosso novo serviço
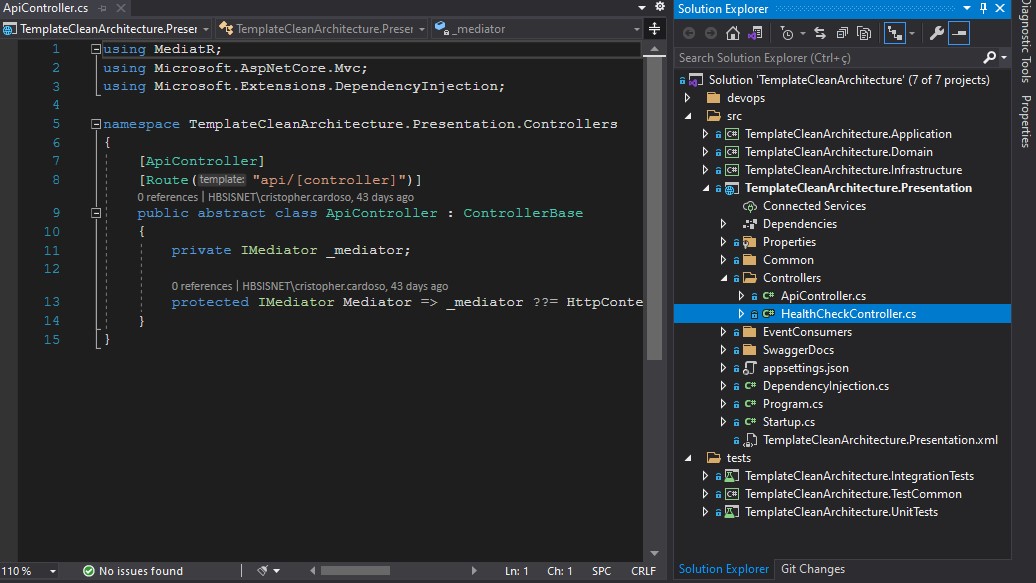
O próximo passo do pipeline é publicar um artefato com o novo serviço. Para termos uma ideia da transformação que é realizada, podemos conferir as imagens a seguir:
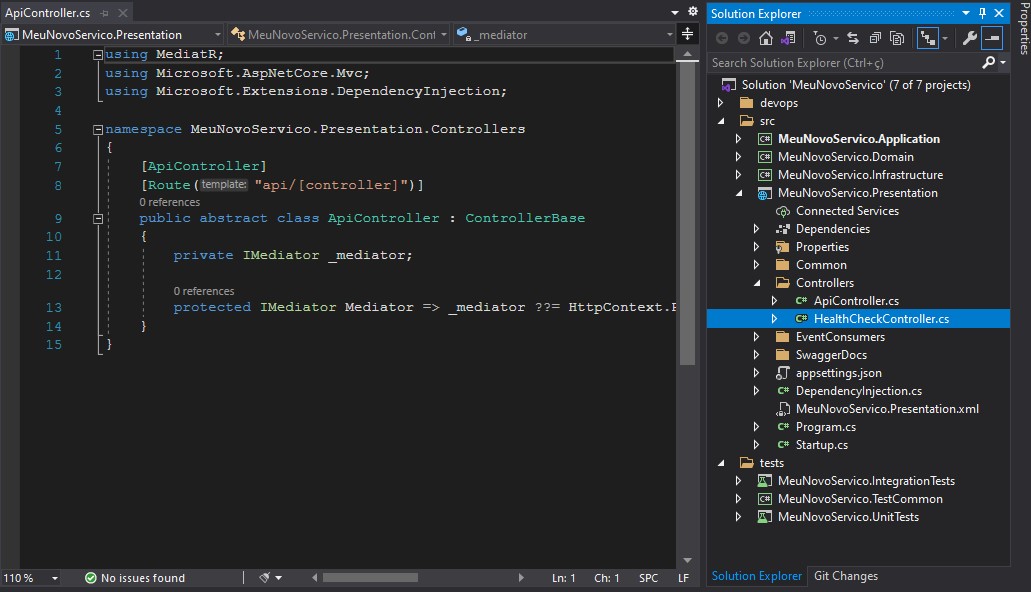
E o resultado do processo de replicação:
Vantagens de copiar um Serviço Exemplar
Um aspecto importante dessa abordagem, é que estamos lidando não apenas com um template de serviço que pode ser copiado livremente para gerar novos serviços, mas com um template que pode ser tratado como um serviço vivo.
Um serviço vivo tem certas características:
- Tem uma pipeline de integração contínua que roda normalmente, como qualquer outro serviço
- Pode ser implantado dele em ambientes não-produtivos
- Pode concentrar boas práticas e tomar proveito das expertises do time
Para tirar o máximo de um “template vivo”, temos que garantir que ele proporcione um começo suave e rápido para o desenvolvimento de novos serviços. Nas seções a seguir, listo algumas dicas baseadas no aprendizado do meu time ao usar essa abordagem na Ambev Tech.
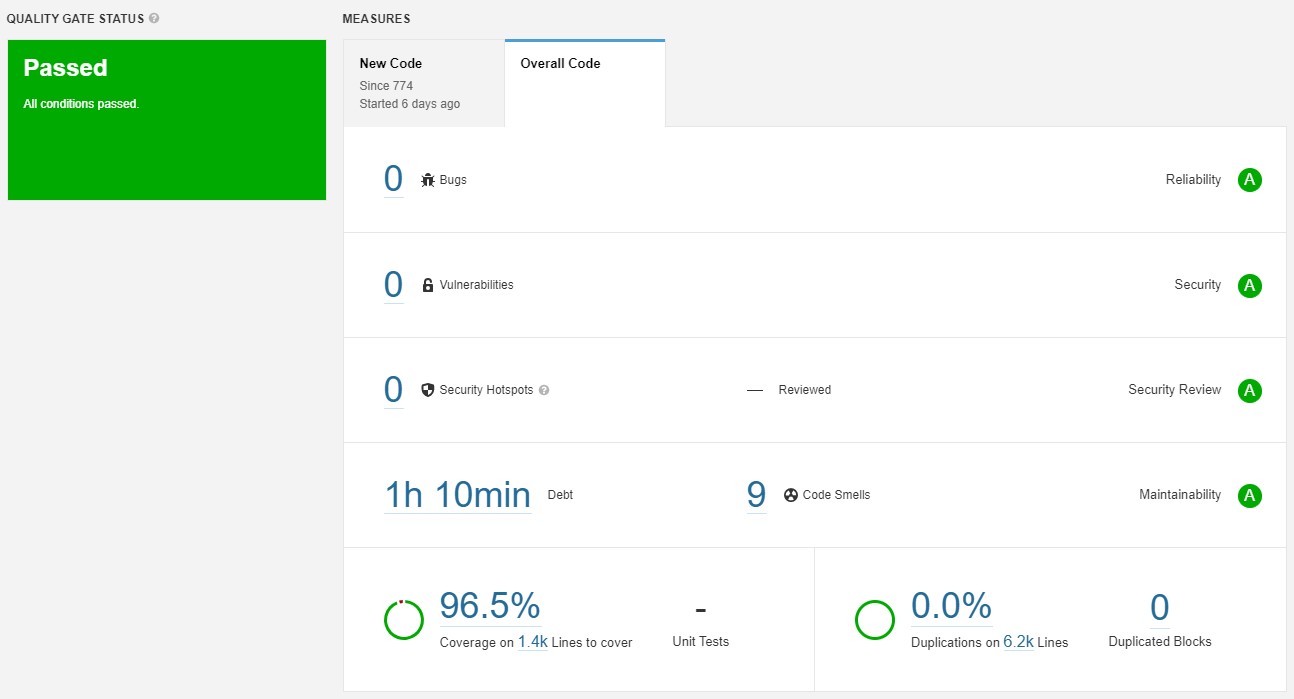
Alta cobertura de código
É muito importante que todo o código do template tenha um índice de cobertura bastante alto. No nosso caso, buscamos manter a cobertura do template mais alta que a dos serviços produtivos. Este item é importante porque é mais fácil manter a cobertura alta, do que fazê-la subir. Assim, todo novo serviço nasce com uma boa cobertura de código.
Se você está usando uma ferramenta como o SonarQube, também recomendo usá-la para manter o número de code smells o menor possível, e evitar quaisquer problemas de segurança.
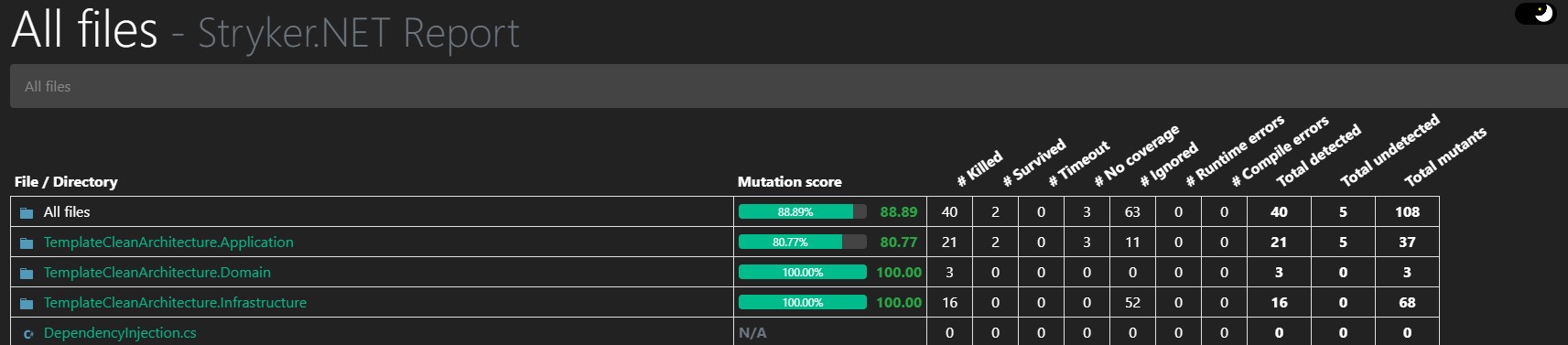
Bom score de mutação
A maioria dos times não utiliza testes de mutação nos seus projetos. Mas como ele é um indicativo da qualidade da suíte de testes, ele pode ser mais efetivo em apontar problemas num projeto de software do que a própria cobertura de testes.
Por isso é interessante que, se o seu time decidir utilizar testes de mutação, cada novo projeto já nasça com eles. Para isso, é importante que o serviço template tenha testes de mutação rodando na sua pipeline.
Se você quiser saber mais sobre testes de mutação, pode conferir meu artigo sobre testes de mutação com Stryker.Net.
Análise de dependências
Se o seu time ou a sua empresa utiliza uma ferramenta de análise de dependências, como o Dependency Track ou Snyk, ela precisa estar rodando no pipeline de integração contínua do template.
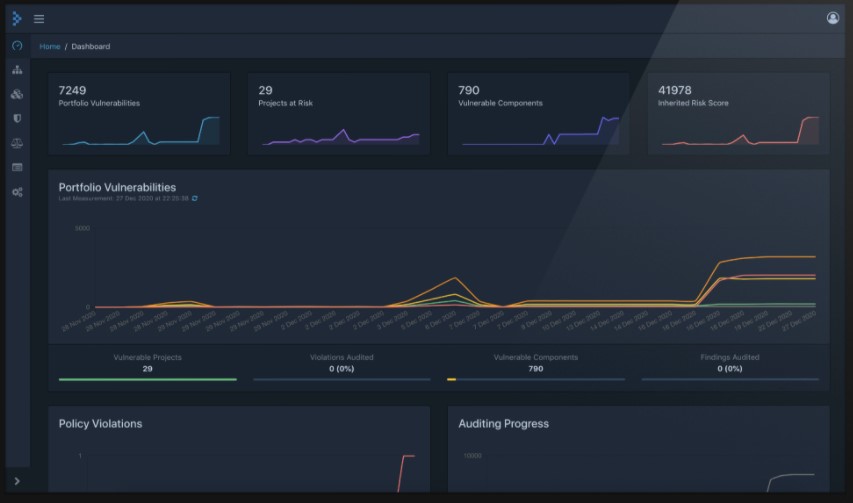
Isso vale para dependências de bibliotecas no backend, no frontend, e também, se possível, para dependências de imagens Docker.
Desta forma, podemos garantir que os novos serviços nasçam com as dependências atualizadas, que têm menor probabilidade de estarem vulneráveis a brechas de segurança.
Documentação
Uma boa estrutura para documentação no template vai ajudar o time a manter a documentação dos novos serviços atualizada.
Por isso, é interessante que o template forneça uma estrutura mínima de documentação que se espera de um novo serviço.
Pensamentos finais
Resumindo, apenas dois elementos são necessários para fazer um gerador simples de serviços:
- Um serviço base, que servirá como template
- Uma pipeline capaz de fazer alguns ajustes no template para gerar o novo serviço. O Replicante ajuda a fazer isso.
Esta abordagem pode agilizar bastante o start de um novo serviço. Basta rodar a pipeline de geração do serviço. Nós usamos algo parecido no meu time, e essa abordagem tem se mostrado eficiente na medida certa.
Por fim, ela funciona com qualquer tecnologia e stack e poderia ser usada facilmente com um projeto Python, Java ou NodeJS.